大模型的到来#
大模型的到来,让越来越多的系统工程师,能够接触在之前难以想象的集群规模尺度上解决复杂的、最前沿的工程问题,且能产生巨大的经济成本和时间成本收益。
不过,让人感慨的是随着 GPT 使用 Transformer 结构去规模化大模型后,随着集群规模的扩展,对于 AI 系统的要求越来越高,可是很多人没办法很好地区分 AI 系统与 AI Infra 之间的关系,因此本节除了重点介绍大模型遇到 AI 系统所带来的挑战,看 AI 系统遇到大模型后的改变,还会去分析 AI 系统与 AI Infra 之间的区别。
大模型介绍#
大模型发展历程#
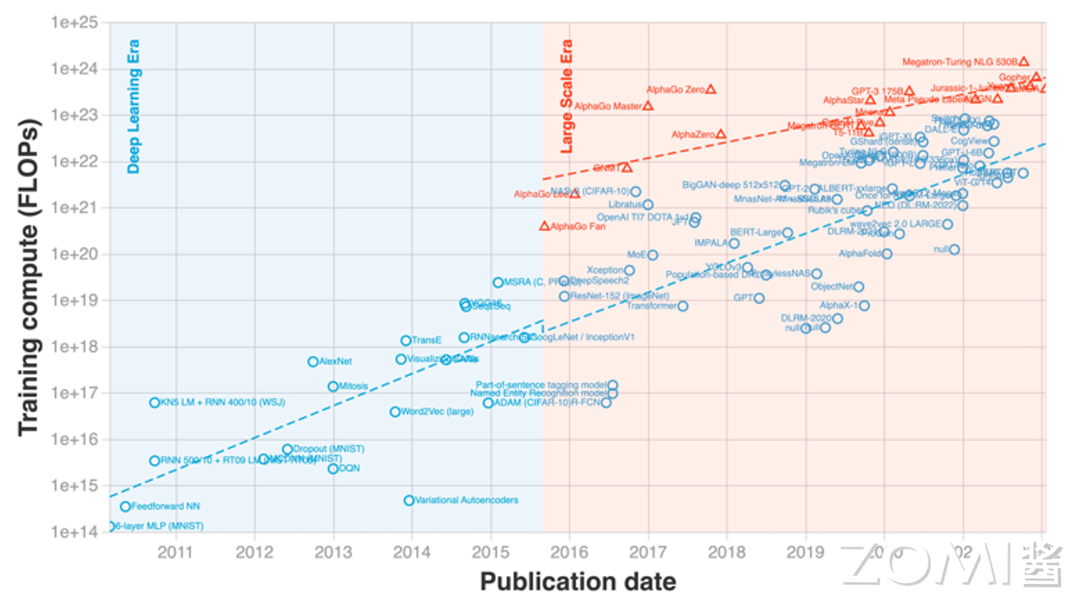
从参数规模上看,AI 大模型先后经历了预训练模型(Pre Training)、大规模预训练模型、超大规模预训练模型三个阶段,每年网络模型的参数规模以 10 倍级以上进行提升,参数量实现了从亿级到百万亿级的突破。截止到 2024 年为止,千亿级参数规模的大模型成为主流。
{kind=link}
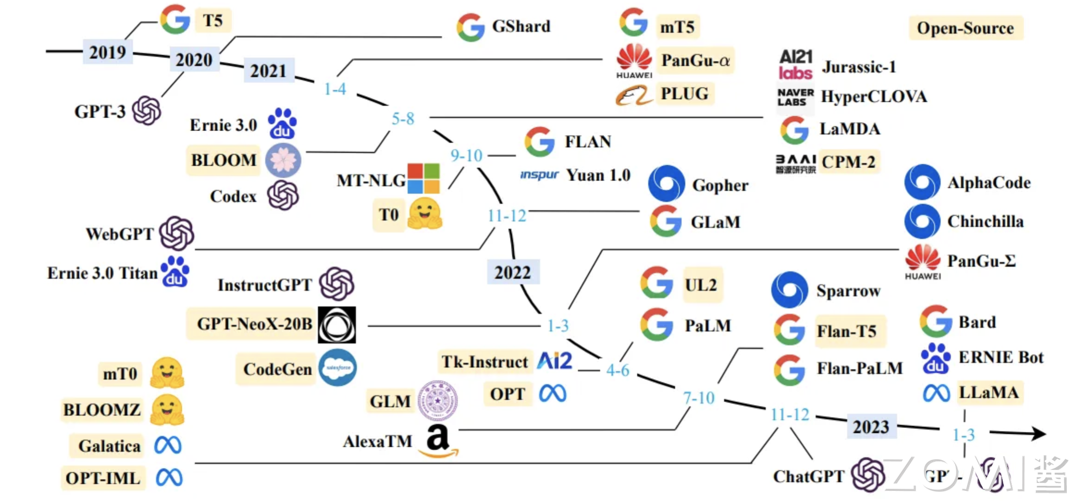
从技术架构上看,如图所示 Transformer 架构是当前大模型领域主流的算法架构基础,由此形成了 GPT 和 BERT 两条主要的技术路线,其中 BERT 最有名的落地课程是谷歌的 AlphaGo。在 GPT3.0 发布后,GPT 逐渐成为大模型的主流路线。综合来看,当前几乎所有参数规模超过千亿的大型语言模型都采取 GPT 模式,如国外有 Grok、Gaulde,国内有百度文心一言,阿里发布的通义千问等。
{kind=link}
从大模型的支持模态上看,AI 大模型可分为大语言模型(Large Language Model,缩写 LLM),视觉大模型(Large Vision Model,缩写 LVM)、多模态大模型(Large Multimodal Model,缩写 LMM)、图网络大模型(Large Graph Model,缩写 GLM)、科学计算大模型(Large Science Model,缩写 LSM)等。AI 大模型支持的模态呈现丰富化发展、更加多样,从支持文本、图片、图像、语音单一模态下的单一任务,逐渐发展为文生图、文生视频、图解析文字等支持混合多种模态下的多种任务。
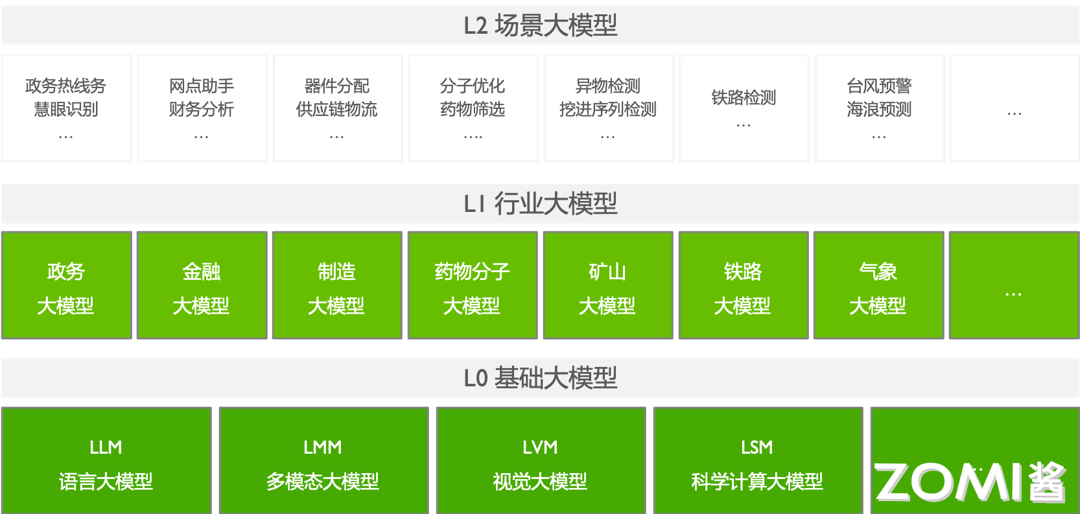
从应用领域上看,大模型可分为 L0、L1、L2 三层。其中 L0 层面是通用基础大模型,涉及到 LLM、LVM、LMM、GLM 等等,通用大模型是具有强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”,ChatGPT、华为盘古都是通用大模型;L1 是构建在 L0 基础上面向行业进行训练的行业大模型(包含政务、金融、制造、矿山、铁路等行业),行业大模型利用行业知识对大模型进行微调,让 AI 完成“专业教育”,以满足在能源、金融、制造、传媒等不同领域的具体需求,如金融领域的 BloombergGPT、航天-百度文心等;而 L2 层则是面是面向一些具体细分行业,通过工作流等从 L1 行业大模型中抽取的符合场景需求,进行针对具体的行业数据机型微调后,使模型处于更加细分领域的场景中应用。
{kind=link}
当前,AI 大模型的发展正从以不同模态数据为基础过渡到与知识、可解释性、学习理论等方面相结合,呈现出全面发力、多点开花的新格局。
大模型发展阶段#
AI 大模型发展历经三个阶段,分别是萌芽期、探索期和爆发期,其中萌芽期主要是指传统神经网络模型的发展历程和阶段,以小模型为技术主导。
萌芽期(1950-2005)
以 CNN 为代表的传统神经网络模型阶段。1956 年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI 发展由最开始基于小规模专家知识逐步发展为基于机器学习。1980 年,卷积神经网络的雏形 CNN 诞生。1998 年,现代卷积神经网络 CNN 的基本结构 LeNet-5 诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型。
在萌芽期阶段,小模型的研究为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续 AI 框架的迭代及大模型发展具有开创性的意义。此时在自然语言处理 NLP 的模型研究都是在研究基于给定的数据集,在特定的下游任务,如何设计网络模型结构、调整超参、提升训练技巧可以达到更高的任务分数,因此出现了 Word2vec、RNN、LSTM、GRU 等各种 NLP 模型结构。
探索期(2006-2019)
以 Transformer 为代表的全新神经网络模型阶段。2013 年,自然语言处理模型 Word2Vec 诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。2014 年,GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。2017 年,谷歌颠覆性地提出了基于自注意力机制的神经网络结构 Transformer 架构,奠定了大模型预训练算法架构的基础。
2018 年,OpenAI 和谷歌分别发布了 GPT-1 与 BERT 大模型,其中 GPT 系列主要使用了 Transformer 架构的 Decoder 部分,BERT 系列主要使用了 Transformer 的 Encoder 部分,Transformer 的出现意味着预训练的语言大模型 LLM 成为自然语言处理 NLP 领域的主流。在探索阶段,以 Transformer 为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
此时无论是基于 Transformer 的 Encoder-Decoder 双编码结构,亦或是类似于 BERT 和 GPT 的单编码结构,业界不断涌现出了 AELM、T5、LLAMA 及其各种变体,在大语言模型 LLM 方向百家争鸣。其模型的大小大多在 1B 以下 (如 BERT-Large 340M,T5-Large 770M、GPT-2 1.5B),训练所需的数据集大小一般不超过 10B。这样的任务,大部分高校、科研院所的有限计算资源(高性能 GPU 服务器)上使用 DeepSpeed 等分布式并行框架,都可以比较方便的训练起来。
爆发期(2020-至今)
以 GPT 为代表的预训练大模型阶段。2020 年,OpenAI 公司推出了 GPT-3,模型参数规模达到了 1750 亿(175B),成为当时最大的语言模型,并且在零样本(Zero Shot)学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练(Code Pre Training)、指令微调(SFT)等开始出现, 被用于进一步提高推理能力和任务泛化能力。不过,从 GPT-3 起,LLM 在行业的玩法变了。Scaling Laws 揭示了模型大小和数据量才是大模型能力的最关键要素,模型大小迅速从 1B 膨胀到了 175B,数据量从 10B 膨胀到了 1T 以上,随之而来的是训练成本的极速增加。
2022 年 11 月,搭载了 GPT3.5 的 ChatGPT 横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。2023 年 3 月,最新发布的超大规模多模态预训练大模型 GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。
由于计算量 FLOPs 翻了一万倍,LLM 不再是学术界能训得起的了,至少 500W 美金一次的训练成本,只有少数头部 AI 企业能有机会训练足够大规模的预训练大模型。同时数据迅速从类似 ImageNet 的开源数据集,演化为爬取、清洗、整理全互联网数据。LLM 从学术研究逐步演变成了数据工程科学。在巨量的数据、模型参数、计算资源下,模型结构和调优算法不再显得过于重要,各家大模型公司实际上比的是谁的数据收集的多、质量清洗的好、数据配比最优,实现大模型的工程能力最好。
如 OpenAI ChatGPT 的巨大成功,就是在微软 Azure 强大的算力以及 wiki 等海量数据支持下,使用 Transformer 架构的 GPT 模型,坚持 Scaling Law 原则下,以及人类反馈的强化学习(RLHF)进行精调的策略下取得的巨大成功。
不过呢,在现金的大模型爆发期,使用千卡 A100 训练千亿大模型,也是 AI 系统的的瓶颈。国外以英伟达为代表,开源了 Megatron-LM 分布式并行加速库,为复现 GPT-3 提供了业界最佳实践;同时提供了集群组网的基础解决方案实践,使得 AI 系统的开发和调优时间被极大缩短。
AI 系统对大模型影响#
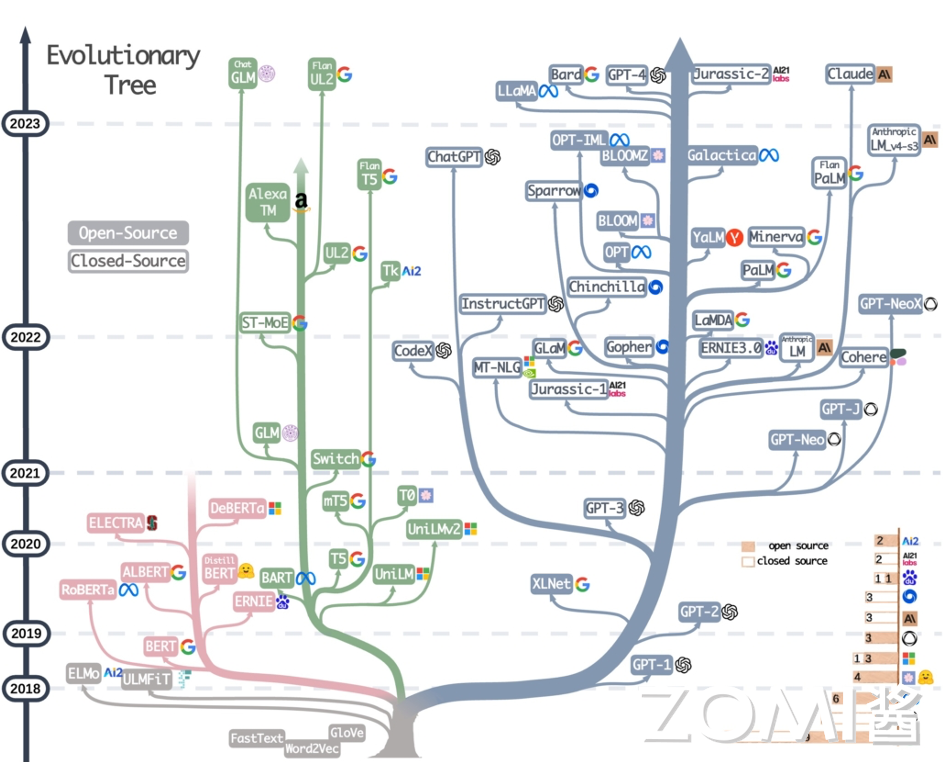
大模型进入了爆发期后,在 LLM 进化树中,BERT(Encoder-Only)、T5(Encoder-Decoder)、GPT(Decoder-Only)分别代表了不同的架构方向。那为什么在大模型时代,曾经风光无限的 BERT 家族和 T5 家族会逐渐没落了?
{kind=link}
从纯算法模型结构上,谷歌的 T5 是比 GPT 更加优雅的神经网络模型结构,但是由于 T5 的模型结构不是线性的,因为在 Decoder 和 Encoder 之间有复杂的连接关系(即对应的 Cross Attention 或者叫做 Cross Condition),导致 T5 在真正大规模堆叠的时候,实际上在工程领域,很难通过分布式并行高效的执行起来。因此,在目前已知的分布式并行优化上,T5 很难通过规模化扩展模型的规模,Scale 到千亿参数以上。
针对直接基于 Decoder-Only 实现的 GPT 模型,在工程领域实现分布式并行优化,会比 T5、BERT 等网络模型更加容易实现。或许不同的算法结构对于网络模型的具体效果上互有高低,但是在模型规模继续 Scale up 的大模型时代,工程上更容易实现分布式并行、更容易扩展、训练 Token 效率更高的模型,一定是更具备优势的,这就是 AI 系统反过来影响算法发展,对算子作出的一种选择作用。
因此,我们正在迈进 AI 系统开始影响和决定大模型的发展方向的时代。也是称为计算机 AI 系统相关的工程人员最好的时代,我们可以切身地接触在之前难以想象的集群规模尺度上解决复杂的、最前沿的工程问题,且能为不同的网络模型算法,带来巨大的经济成本和时间成本收益。
目前预训练大模型成本居高(GPT-4 训练一次的成本超过 5000W 美金),再往上翻倍探索下一个 FLOPs 数量级也变得十分困难。因此百亿级别和千亿级别的 MoE 架构开始慢慢成为了大模型时代考虑的下一个主流方向,即如何用更低的成本,更快地训练和推理更大规模的模型,这将是未来 AI 革命中的主流主题。
客观地预测,未来大模型算法研究也必然朝着 AI 系统的方向去探索:稀疏化(Sparse)将会是今明几年内,学术界和工业界主战场,训练速度每提升 5%,都将节省上千万人民币的训练成本,并在大模型竞赛中占据优势地位。
即使是稠密的大模型,也在探索诸如 GQA(Grouped Query Attention)等算法结构上的优化,推理阶段考虑如何使用 MHA(Multi-Head Attention)通过离线的方式转换成为 GQA,减少推理的计算量。这些算法优化并不是为了提升模型的使用效果,而是希望成倍的节省推理阶段 Inference 时的 KVCache 显存和计算峰值 Flops,从而使大模型可以在保存低时延下实现更高的吞吐性能。
因此,如果你是一个想在大模型时代有所建树的算法研究员,不懂 AI 系统将会是非常吃亏的事情。如果你来设计一个新的大模型算法,一定需要在设计阶段就要考虑如下问题:
新设计的网络模型结构算法是否更容易进行分布式并行计算?
新设计的网络模型结构算法需要多久的时间才能训练出更好的效果?
新设计的网络模型结构算法如何实现超长的记忆能力(长上下文 Sequence Length?
新设计的网络模型结构算法如何训练和如何推理?
因此,如果你是一个想在大模型时代有所建树的系统研究员,不懂 AI 系统将会是非常吃亏的事情。如果你来设计一个系统,满足未来的算法技术发展趋势,一定要在设计阶段开始就要考虑如下问题:
网络模型结构算法如何实现各种并行时所需的通信量更低?
网络模型结构算法如何优化实现更少计算量、 更少的显存需求、 更容易进行推理?
如何设计编译器使得网络模型计算自动优化、实现通信量、计算量、显存占用更少?
如何设计编译器使得网络模型结构算法能够适配到不同的 AI 加速器上执行计算?
如何设计 AI 计算集群的网络拓扑,减少网络拥塞,降低网络传输耗时,提升线性度?
换言之,在大模型时代,如果提出新的网络模型算法结构可能有 5% 的效果提升,但是引入了额外 50% 的训练成本,那这个新的网络模型算法一定是一个负优化算法,而且不一定能够实现出来,还要支撑各种消融试验和对比实验。50% 的训练成本,基于 Scaling Laws 可以在原模型上多增加 50% 的上下文长度,或者网络模型的规模 Scale up 增大一半,可能带来的最终效果提升,远大于新设计出来的网络模型结构算法所提升的 5%。
AI 系统对于新算法研究的重要性日益凸显,如今已不仅仅是算法研究的辅助工具,而是成为了其不可或缺的一部分。随着 AI 系统的不断发展和进步,其在大模型研究中的影响力也愈发显著。可以说,AI 系统已经成为了大模型研究中不可或缺的重要力量。因此,对于 AI 系统的深入研究和应用,对于推动大模型研究的进步和发展具有十分重要的意义。
AISystem 与 AIInfra#
在某种意义上,很多算法研究者或者系统研究者,没有很好地区分 AI System 和 AI Infra 之间的关系。本节将会重点介绍 AI System 和 AI Infra 之间的区别,并给出其不同的定义:
AI Infra(AI 基础设施)是连接 AI 训练推理全流程的软件应用,及 AI 中间件基础设施。主要包含大模型从设计、生产到应用等全流程所配套的横向软硬件设施。
AI System(AI 系统)是 AI 时代连接硬件和上层应用的中间层基础设施。主要包含底层系统架构、编译器、AI 框架等纵向的基础软硬件设施。
../images/01Introduction/05Foundation05.png
{kind=link}
AI Infra(AI 基础设施)#
大模型时代对 AI 基础设施的需求,与传统机器学习时代的工具栈侧重点有所不同。AI Infra 主要是从 AI 训练模型、构建 AI 赋能应用的工作流视角出发,更加关注 AI 在大模型开发、训练和推理部署的相关环节,即从 AI 训练和推理的环节过程作为代表,历经从数据准备、模型训练、模型部署、产品整合等不同环节。因此更强调的是从大模型数据准备到训练、推理、应用横向的软硬件基础设施。
../images/01Introduction/05Foundation06.png
{kind=link}
数据准备#
数据准备过程包括提供高质量数据、数据标注、特征数据库、生成数据等多方面。在大模型探索期,有部分学者认为大模型主要使用无监督学习过程,即输入当前单词序列 Tokens,预测下一个单词的概率 Token。因此数据准备在大模型,特别是 LLM 语言大模型变得并不是十分的重要。
但实际上,数据准备无论在小模型时代,还是大模型都是耗时较久、较为重要的一环。无监督学习虽然在一定程度上,降低对标注数据的需求,但 RLHF、SFT 等大模型的训练和微调机制体现了,大模型使用无监督学习机制降低了对标注数据的需求,但 RLHF(Reinforcement Learning from Human Feedback)等新的微调环节,体现了高质量标注数据对模型效果的重要性和意义。
对高质量标注数据的重要性,未来超大规模参数量的模型对海量训练数据的需求将会持续增加。部分研究者则认为,当互联网上可用的开源数据和其他数据耗尽的时候,会由更多的合成数据来满足大模型的训练需求。模型参数量规模大幅提升,带来日益增长的训练数据需求,长期看可能无法仅通过互联网和真实世界所提供的数据来满足,生成数据提供一种 AIGC 反哺 AI 数据训练的解法。
除了高质量的数据,数据标注也尤为重要。数据标注位于模型开发的最上游,对图像、视频、文本、音频等非结构化原始数据添加标签,为 AI 提供人类先验知识的输入。
目前,越来越多负责预训练、强化学习等的 AI 科学家也参与到数据准备中;开源论文 LLAMA2 也有一段强调高质量数据对模型训练结果影响的表述,Meta 与第三方供应商合作收集了近 3 万个高质量标注,又向市场证明了高质量数据标注工作的重要性。
模型训练#
模型训练的过程中对模型库的需求量非常大,随着 AI 框架持续迭代,AI 软件工具协助实验管理也变得越来越重要。基于大模型微调的模型越来越多,因此需要能够高效便捷地获取和存储预训练模型的模型库。同时也催生更适应于大模型的大规模预训练所需的加速库,其中最为核心的则是底层的分布式并行加速库。
首先,预训练的大模型具有一定通用性(即 LO 通用预训练大模型),开发者们可以“站在巨人的肩膀上”,在预训练模型的基础上通过少量、增量数据训练出 L1 模型,解决垂类场景的需求。此时,要想高效便捷地获取模型,则需要一个集成托管各类模型的模型库,从而把握从数据到模型的工作流入口。
其中,模型库顾名思义是一个托管、共享了大量开源模型的平台社区,供开发者下载各类预训练大模型,除模型外,主流的 Model Hub 平台上还同时提供各类共享的数据集、应用程序等。目前国外较为代表性意义的社区有 Hugginface 社区,国内有 ModelScope(阿里达摩院推出的 AI 开源模型社区)等课程。
其次,催生出更适应大规模训练需求的分布式加速库。过去传统 CPU 的分布式计算,大数据已带动了以 MapReduce、Spark 为代表的分布式计算引擎的发展。如今,大模型的预训练阶段需要大规模的 AI 集群,分布式加速库可以为大模型提供多维分布式并行能力,让大模型能够在 AI 集群上快速训练/推理,还能提升模型和算力利用率,提升 AI 集群的线性度。业界流行分布式加速库有 AscendSpeed、Megatron-LM、DeepSpeed、ColossalAI、BMTrain 等等,大部分是基于 PyTorch 等 AI 框架之上针对大模型分布式训练,设计的分布式加速库进行特殊优化。
此外,模型训练过程涉及多次往复的修改迭代,无论是 ML 还是 LLM 都需要借助实验管理工具进行版本控制和协作管理。实验管理过程主要是记录实验元数据,辅助版本控制,保障结果可复现。
因在模型预训练是一种实验科学,需要反复修改与迭代,同时由于无法提前预知实验结果往往还涉及版本回溯、多次往复,因此模型的版本控制和管理就较为必要,实验管理软件可以辅助技术人员和团队追踪模型版本、检验模型性能。Weights and Biases(W&B)和 Neptune 等上层应用能跟踪机器学习实验,记录实验元数据,包括训练使用数据集、框架、进度、结果等,支持以可视化的形式展现结果、多实验结果对比、团队协作共享等。
模型部署#
模型部署层面更关注的是模型从实验和理论走向真实业务,并在真实业务环境和场景中部署并提供监控等内容。
大模型在端侧将会突破释放出大规模应用落地的潜能,更多的大模型从实验环境走向生产环境。借助模型部署工具,能够解决大模型在不同 AI 框架的兼容性差的问题,并提升大模型运行速度。从实验走向生产的重要环节。模型部署指把训练好的模型在特定环境中运行,需要尽量最大化资源利用效率,保证用户使用端的高性能。
模型监控通过对模型输出结果和性能指标的追踪,保障模型上线后的可用性。过去由于 ML 模型的非标和课程制,大规模、持续性的模型部署和监控需求未被完全激发出来,大模型的端侧突破,同时也会整体拉动大模型部署和监控的需求。
此时针对打模型的可观测性、保障性、可靠可用可纬测性就变得尤为重要。可观测性在传统 IT 系统运维中就是重要的数智化手段之一,通过监控各类机器、系统的运行数据对故障和异常值提前告警。大模型监控同理,监测模型上线后的数据流质量以及表现性能,关注大模型可解释性,对故障进行根因分析,预防数据漂移、模型幻觉等问题。
应用整合#
大模型端的突破释放出更多应用落地的潜能,由此催生出对应用产品整合相关工具产品的需求,其中较为关键的是向量数据库、专门针对大模型的应用编排工具、AI Agent 具身智能相关组件。
向量数据库因为大模型 RAG 流程的使用而火起来,目前最直接的作用是作为大模型的外部知识库。让通用大模型具备专业知识主要有两种途径,第一种方案是,通过微调将专有知识内化到大模型的权重参数里面;另一种则是利用向量数据库给大模型增加外部知识库。向量数据库和大模型的具体交互过程分为:首先将专业知识库的全量信息通过 Embedding Model 嵌入模型转化为向量 Vector 后储存在向量数据库中。用户输入数据指令 Prompt 时,先将 Prompt 向量化,并在向量数据库中检索最为相关的内容,最后将检索到的相关向量信息和初始 Prompt 一起输入给大模型进行计算。
应用编排工具则是对大模型应用的“粘合剂”。应用编排工具作为一个封装了各种大模型应用,提供大模型开发所需逻辑和工具的代码库。初始化的大模型存在无法联网、无法调用其他 API、无法访问本地文件、对 Prompt 要求高、生成能力强但内容准确度无法保证等问题,应用编排框架提供了相应功能模块,帮助实现从大模型到最终应用的跨越。其中以 LangChain 作为代表是当下最流行的框架之一,主要包含以下几个模块:1)Prompt 实现指令的补全和优化;2)Chain 调用外部数据源、工具链;3)Agent 优化模块间的调用顺序和流程;4)Memory 增加上下文记忆。
集成开发环境,如交互式的 Notebook 逐渐流行。在上述 AI 建模流程中,开发者需要处理大量代码编写、分析、编译、调试等工作,可以直接在对应环节或平台型产品的内置环境中进行,也可以使用专门的集成开发环境并调取所需功能。其中,Notebook 是一种交互式的开发环境,和传统的非交互式开发环境相比,Notebook 可以逐单元格(Cell)编写和运行程序,出现错误时,仅需调整并运行出现错误的单元格,大大提升开发效率,因此近年逐渐流行、深受数据科学家和算法工程师的喜爱,被广泛应用于 AI 算法开发训练领域。
AI System(AI 系统)#
大模型时代对系统以及基础设施的需求,与传统机器学习时代的侧重点有所不同。AI System(AI 系统)更多的是从 AI 的底层软硬件基础设施的角度触发,分为底层硬件系统架构层,软硬件结合的中间件编译层、支撑 AI 训练和推理流程的 AI 框架和 AI 推理引擎,部分还会囊括集群管理和调度平台,对上提供编程语言和集成环境。因此更强调的是从底层硬件到上层应用的纵向软硬件基础设施。
AI 系统关注重点#
训练领域#
训练效率
不管是基于 Transformer 结构的多模态大模型,抑或是语言大模型,在模型结构不改变的情况下软件上能够有极大程度的性能突破似乎变得极其困难。算子优化(XFormers、FlashAttention)加上并行优化策略,已经基本上把在现有跨卡/跨节点的 Rank 间互联带宽下,把 NPU 的算力利用率 MFU 发挥到极致了。此时,在 AI 系统层面需要新 AI 专用硬件的出现,可能会带来新的破局点;另外对于 MOE、Mamba 等创新的网络模型结构的出现,有望挑战 Transformer 统一所有模态的局面。
易用性
分布式并行在过去 1/2 年非常的火热,众多学者都在涌入该领域,几个代表性的工作包括:Ray+JAX based 明星课程 Alpa [OSDI'22],自动并行“泰斗”FlexFlow 升级版 Unity [OSDI'22],主打 PyTorch 兼容和 Transformer 模型的 Galvatron [VLDB'23]。这把火一路烧到了 2023,这一年 arXiv 上其实挂出了蛮多改进性工作,比如在原先自动并行基础上的各种联合优化,但似乎也并没有得到太大的关注。估计 2024 年还是会有一些相关论文出现在顶会上,但关注度可能不会很大。
稳定性/成本:集群容错是一个 2023 年比较热门的话题,也是大型企业造大模型时的真实需求。同时还有一个高度关联的方向,弹性计算,也得到了广泛的关注。早期工作包括 Varuna [EuroSys'22](Best Paper)和 Bamboo [NSDI'23],今年也出现了一些 Competitors,比如 Gemini [SOSP'23], Parcae [NSDI'24]和 Oobleck [SOSP'23]。这些方向 2024 年可能会得到更多关注。
推理
效率:incremental decoding 改变了 LLM 中的部分算子实现机制,但经过 23 年一整年的 Kernel 优化,硬件性能也几乎已经压榨到极限(主要指访存带宽)。展望 2024,在系统效率,尤其是 end-to-end inference latency 这一单一指标上,能比现在 SOTA 方案做的多好其实是要画问号的。一个可能的方向是 speculative decoding;另外如果是围绕其他性能指标如 throughput 和 TTFT/TPOT 展开优化,应该也还有一些可做的空间;如果是能够再牺牲“亿”点点模型效果,不保证输出内容严格对齐的话,那可做的事情就更多了。这部分详细内容可以参考综述论文:Hsword:大模型如何高效部署?CMU 最新万字综述纵览 LLM 推理 MLSys 优化技术
易用性:自动并行在推理侧看起来没有太多有趣的东西,主流框架已经可以把各种并行策略(如 TP/PP)支持的很好了。个人感觉,随着大模型使用场景的复杂性逐渐增加,未来更值得关注的可能是如何把推理引擎更好地和整套 AI Service 产品 Pipeline 相结合,提高整体的部署和服务效率。
稳定性/系统成本:2023 年年底出现的 SpotServe [ASPLOS'24]是首个面向可抢占集群的 LLM 推理系统,通过廉价 Spot Instance 大幅降低推理成本,开创了弹性计算/集群容错+LLM 推理的先河。展望 2024,不管是学术界(如 SkyLab)还是工业界,可能会出现更多相关工作或产品,比如 AnyScale 已经在做 Spot Instance 的支持。
其他方面,其实 LLM 推理还是有很多可做的事情的,但由于准入门槛较低,大家不得不“拼手速”。一个蛮有意思的例子就是,23 年年底几个同期在做 multi-LoRA serving 的 team 几乎同时 release 了论文和系统[1][2][3],某种程度上也说明了目前“卷”的程度。PS:其实 Azure 早在大半年前的对外宣讲中就介绍过了内部的 multi-LoRA serving 优化,只不过没有论文公开。
小结与讨论#
大模型指具有大量参数和计算资源的 AI 模型,通常在训练过程中需要大量的数据和计算能力,并且具有数百万到数十亿个参数。大模型在训练遇到的挑战体现在 4 方面:内存墙、通信墙、调优墙、开发墙,需要通过 AI 系统全栈进行优化。
大模型对 AI 系统冲击严重,不仅仅在集群组网、网络存储、资源调度等硬件,还涉及框架、应用算法、分布式并行、训练到推理全流程软硬件协同。大模型 + AI 系统技术栈与传统 AI 系统技术栈增加了更多细节,和大模型使能层。