03.集合通信操作/原语/算子#
Author by: SingularityKChen
!!!!!!!!!!! 展开一下
本章内容聚焦集合通信操作的基础介绍。集合通信操作也称为集合通信原语或集合通信算子。
XCCL 对通信操作支持情况#
众多集合通信库 XCCL 大模型训练和推理过程中属于数据链路和传输层。其基于网络模型的拓扑及其适配的通信算法,实现和封装具体的通信原语。
下图总结了 MPI 中实现了的常见集合通信算子以及该论文发表时 NCCL、MSCCL、Gloo、oneCCL 和 ACCL 对上述集合通信算子的支持度。我们可以看到,并不是所有 MPI 的通信算子都在 XCCL 中实现。这是因为 MPI 主要针对传统的超算和 HPC,而 XCCL 着重对 AI 计算过程中涉及的通信操作做优化。

!!!!!!!!!!! 文章来源
下图总结了常见的集合通信算子、其实现算法及其适用场景。
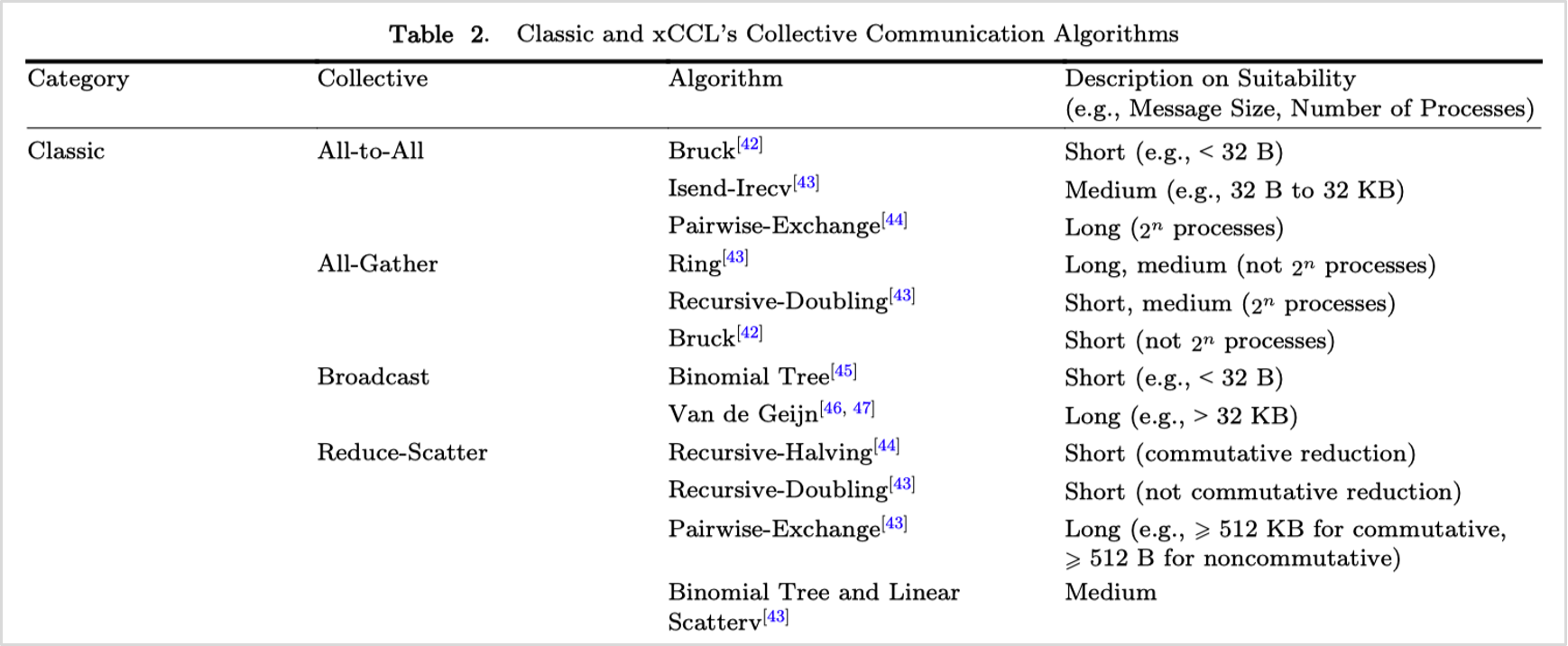
在 NCCL 中,通信操作被分为集合通信与点对点通信两大类。
!!!!!!!!!!! 不要列表,用段落
集合通信
AllReduce
Broadcast
Reduce
AllGather
ReduceScatter
点对点通信
Sendrecv
Scatter
Gather
All-to-All
Neighbor exchange

!!!!!!!!!!! 技术点,不要太口语化
可以发现在表 1 的论文发表后 NCCL 又实现了一些通信算子。
一对多#
本小节将介绍一对多的通信操作—— Broadcast 和 Scatter。
Broadcast#
!!!!!!!!!!! 后面都是,深入打开 Broadcast 的原理,为什么大模型训练过程中,会用到 boardcast,深入深入
Broadcast 操作将单个 Rank 把自身的数据发送到集群中的其他 Rank。
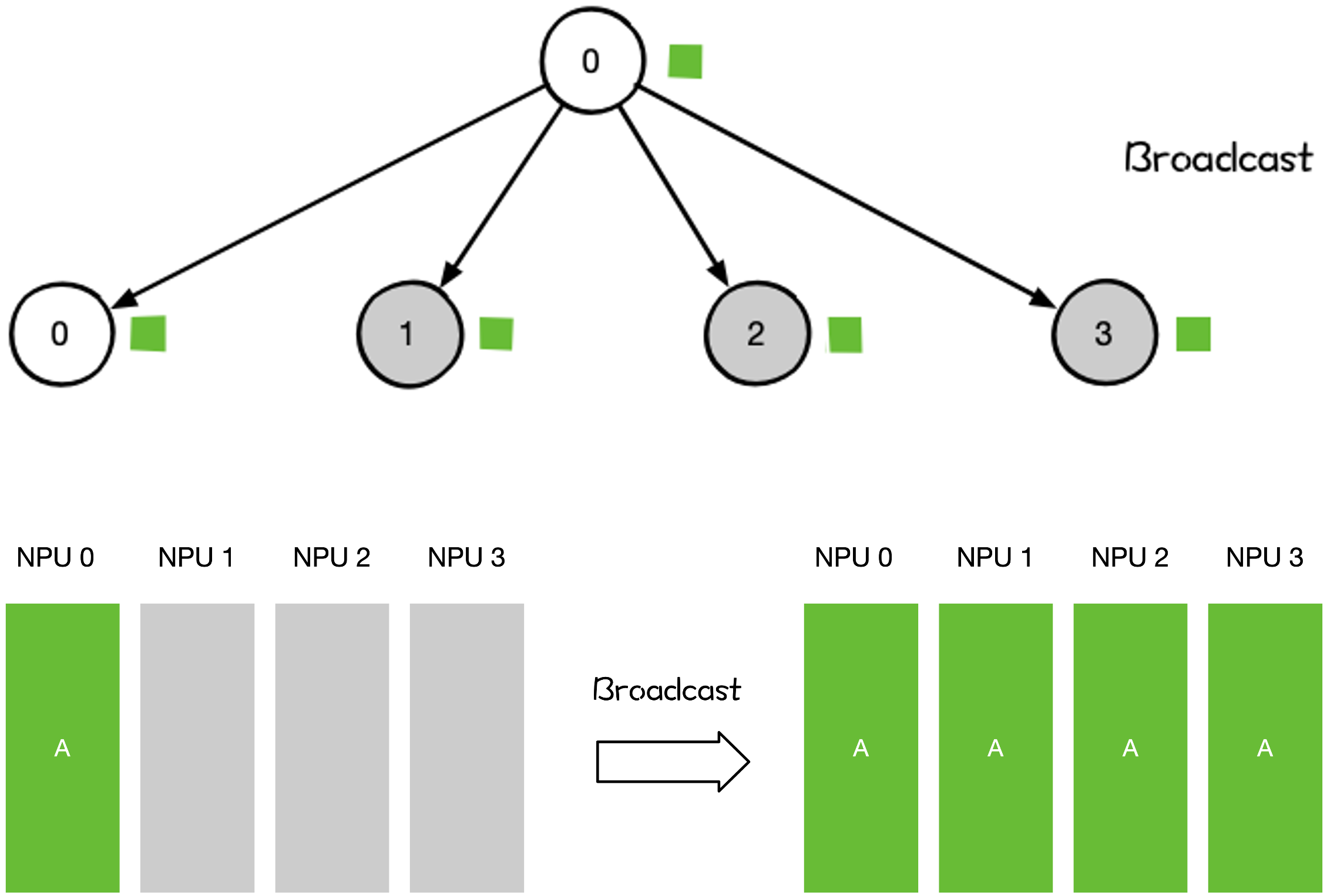
大模型训练和推理过程中,涉及到 Broadcast 的操作有:
网络参数 Init Weight 的初始化;
数据并行 DP 对数据分发初始化;
All-Reduce 操作的一部分;
All-Reduce 可分解为 Broadcast 和 Reduce 两个阶段
Scatter#
Scatter 操作将主节点的数据进行划分并散布至其他指定的 Rank。
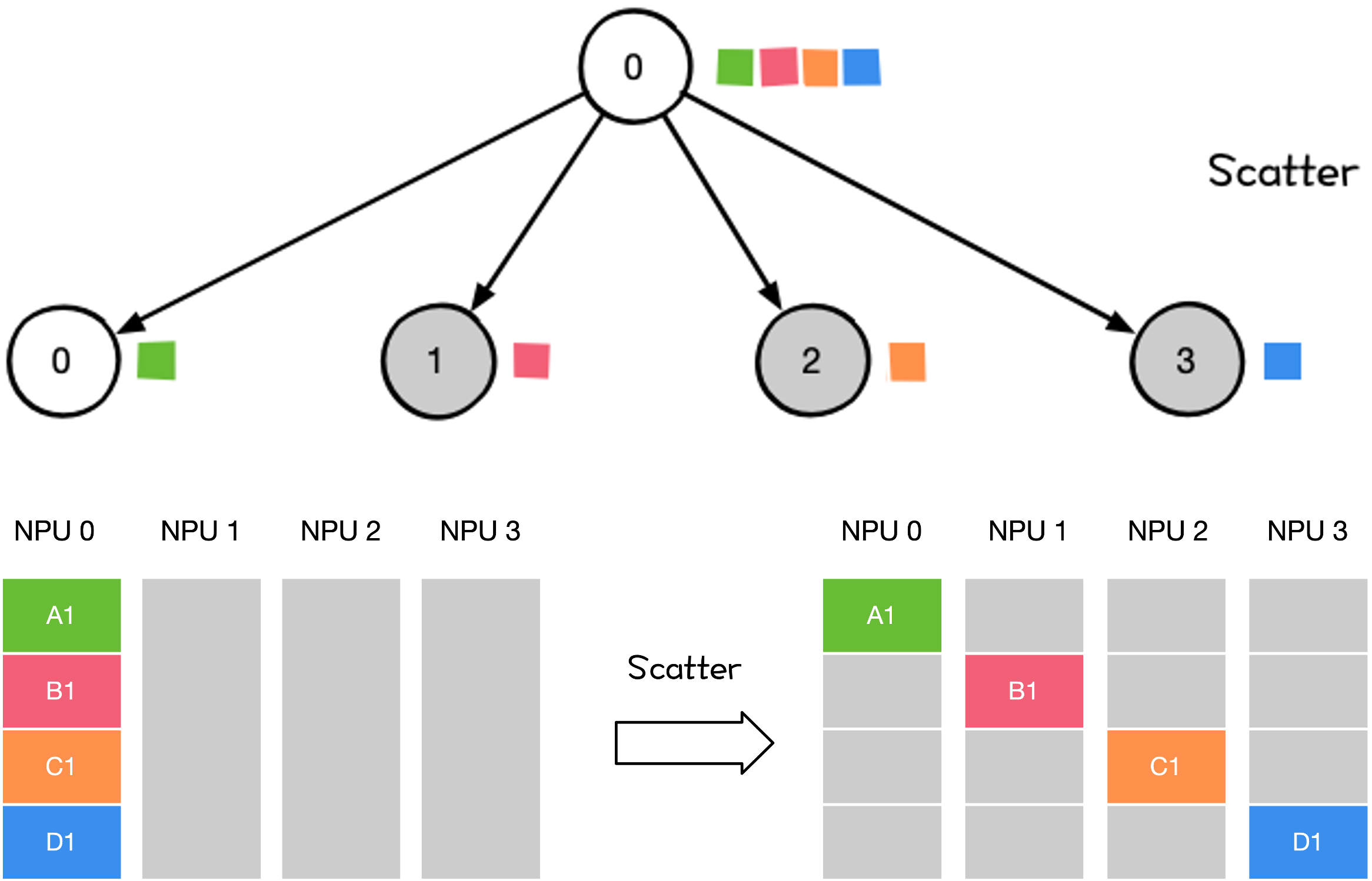
大模型训练和推理过程中,涉及到 Scatter 的操作有:
流水并行(PP)里初始化时将模型权重 Scatter 到不同 Rank 上;
Reduce-Scatter 操作的一部分
Reduce-Scatter 可分解为 Reduce 和 Scatter 两个阶段;
通信操作/原语——多对一#
本小节将介绍多对一的通信操作—— Reduce 和 Gather。
Reduce#
Reduce 操作是把多个 Rank 的数据规约运算到一个 Rank 上。
Reduce 的规约操作包含:SUM、MIN、MAX、PROD、LOR 等类型的规约操作。Reduce Sum 操作示意如下。
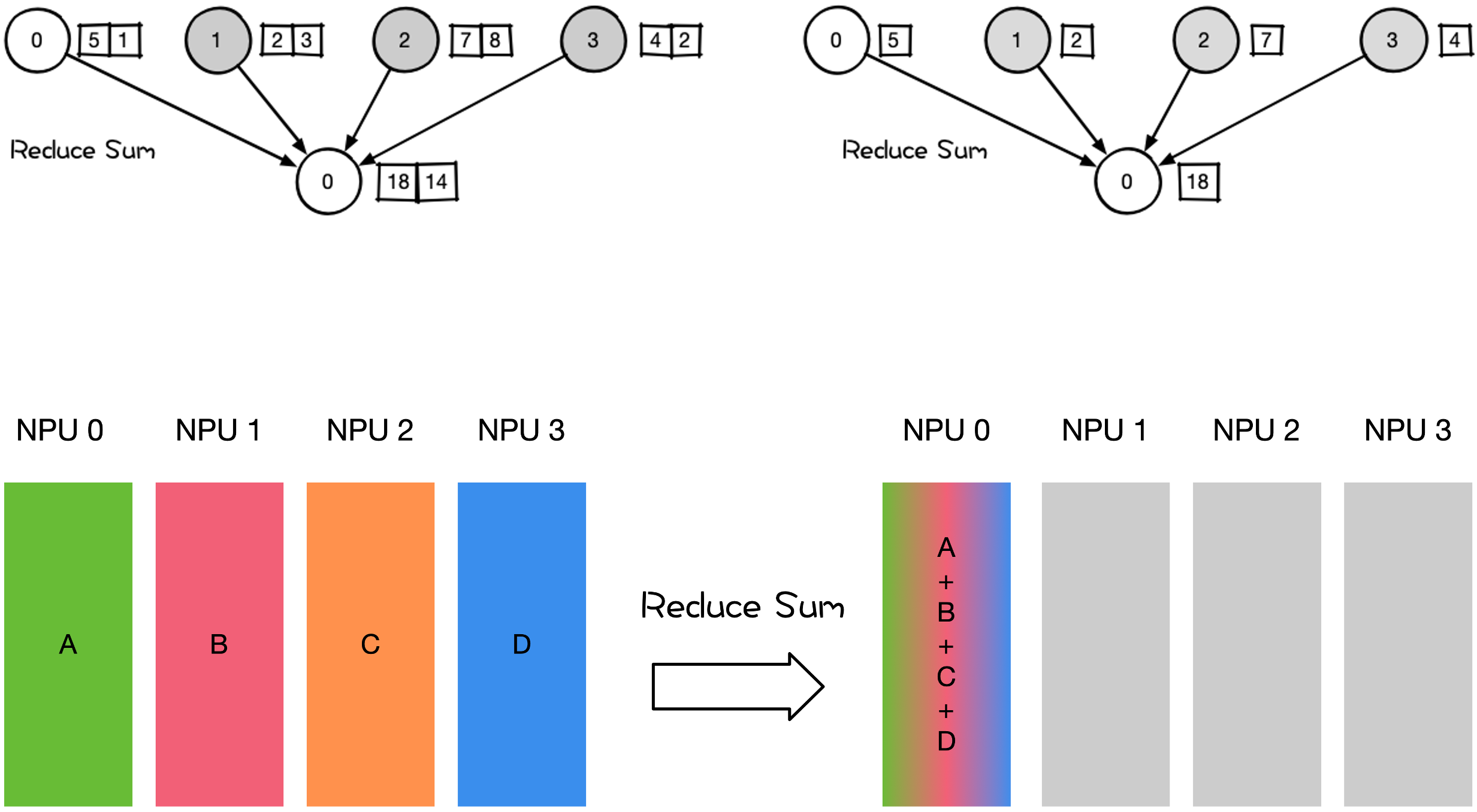
大模型训练和推理过程中,涉及到 Reduce 的操作有:
大模型训练权重 checkpoint 快照保存;
All-Reduce 和 Reduce-Scatter 中的 Reduce 阶段
Gather#
Gather 操作是将多个 Rank 上的数据收集到 Rank 上。Gather 可以理解为反向的 Scatter。
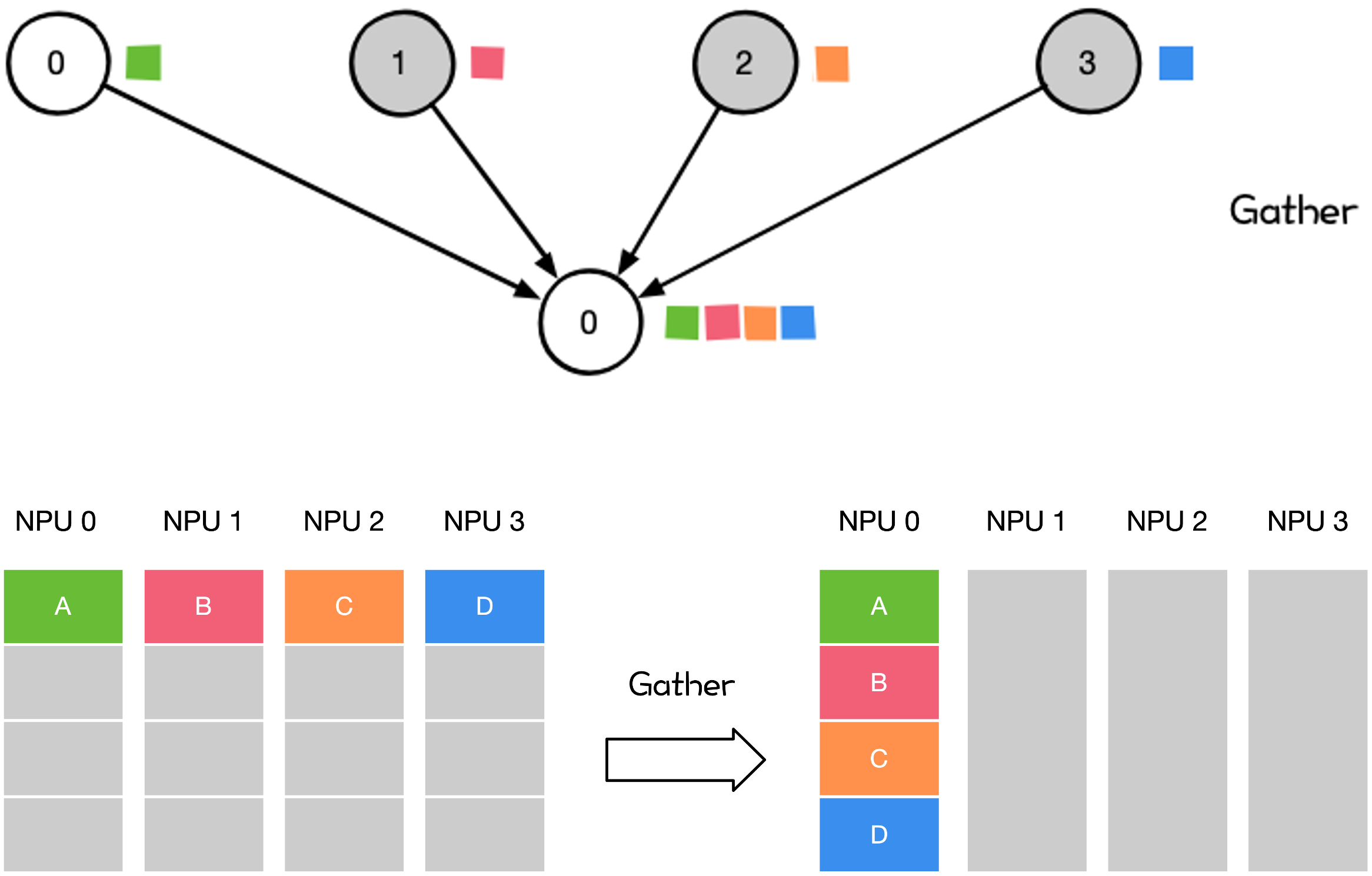
大模型训练和推理过程中,涉及到 Gather 的操作相对较少。
通信操作/原语——多对多#
本小节将介绍多对多的通信操作—— All-Reduce、All-Gather 和 All-to-All。
All-Reduce#
All-Reduce 操作是在所有 Rank 执行相同 Reduce 操作,然后将所有 Rank 数据规约运算得到的结果发送到所有 Rank。
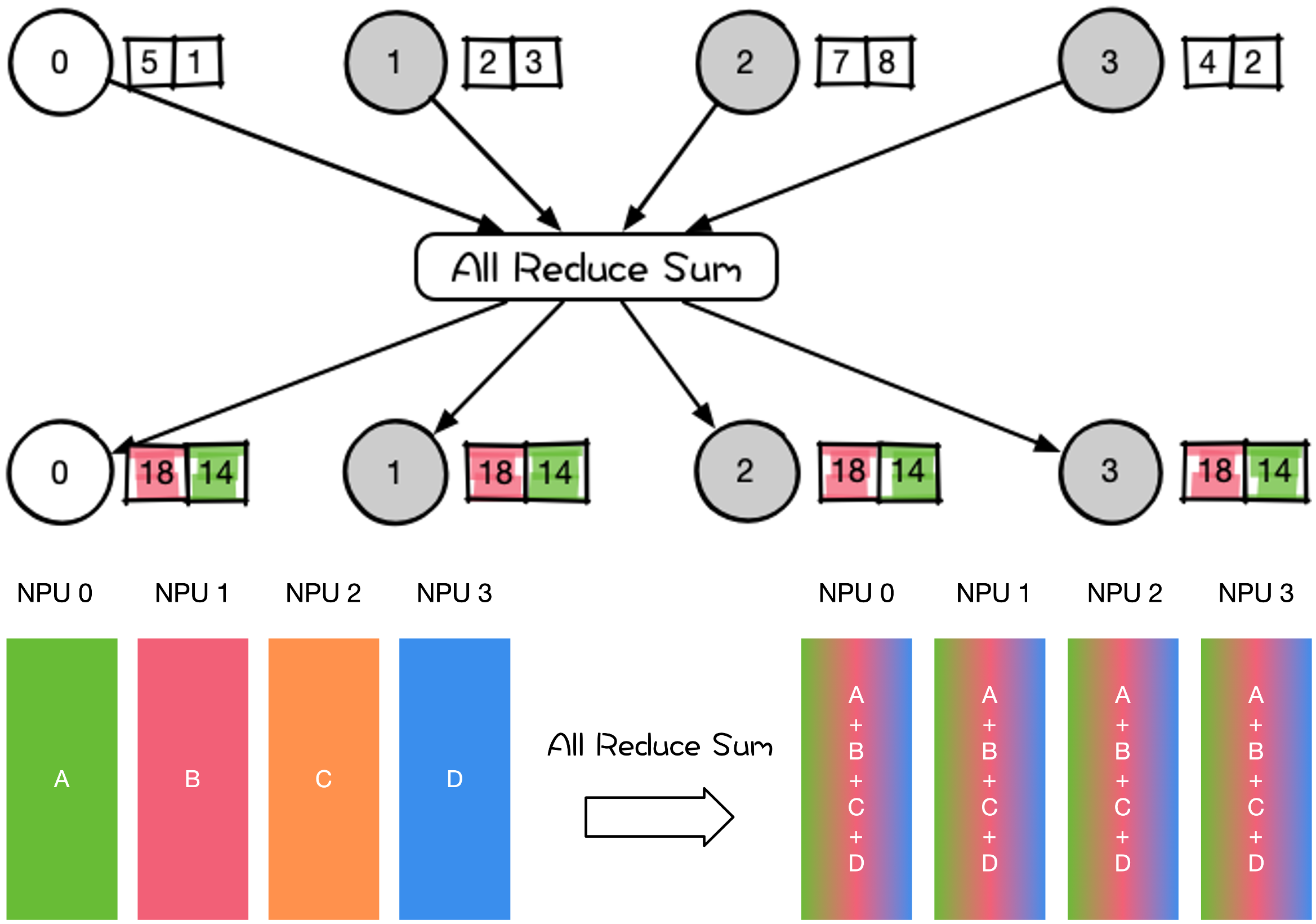
大模型训练和推理过程中,涉及到 All-Reduce 的操作有:
在专家并行、张量并行、序列并行中大量地使用 All-Reduce 对权重和梯度参数进行聚合。
数据并行 DP 各种通信拓扑结构,比如 Ring All-Reduce、Tree All-Reduce 里的 All-Reduce 操作;
All-Gather#
All-Gather 操作是从所有 Rank 收集数据并分发所有 Rank 上。
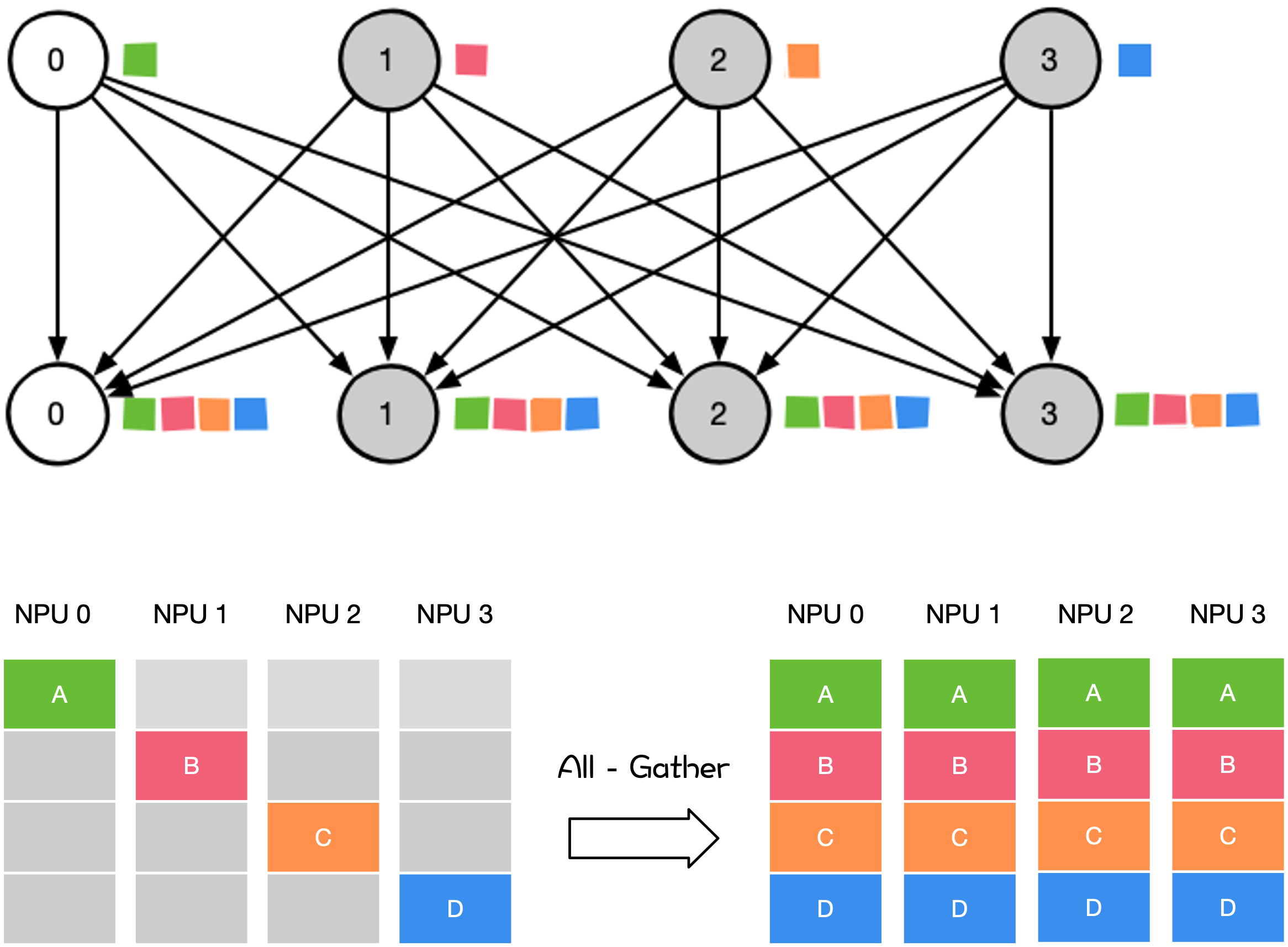
大模型训练和推理过程中,涉及到 All-Gather 的操作有:
在专家并行、张量并行、序列并行中对权重和梯度参数进行聚合。
模型并行里前向计算里的参数全同步,把模型并行里将切分到不同的 NPU 上的参数全同步到一张 NPU 上才进行前向计算。
Reduce-Scatter#
Reduce-Scatter 操作是在所有 Rank 上都按维度执行相同的 Reduce 规约操作,再将结果发散到集群内所有的节点上。
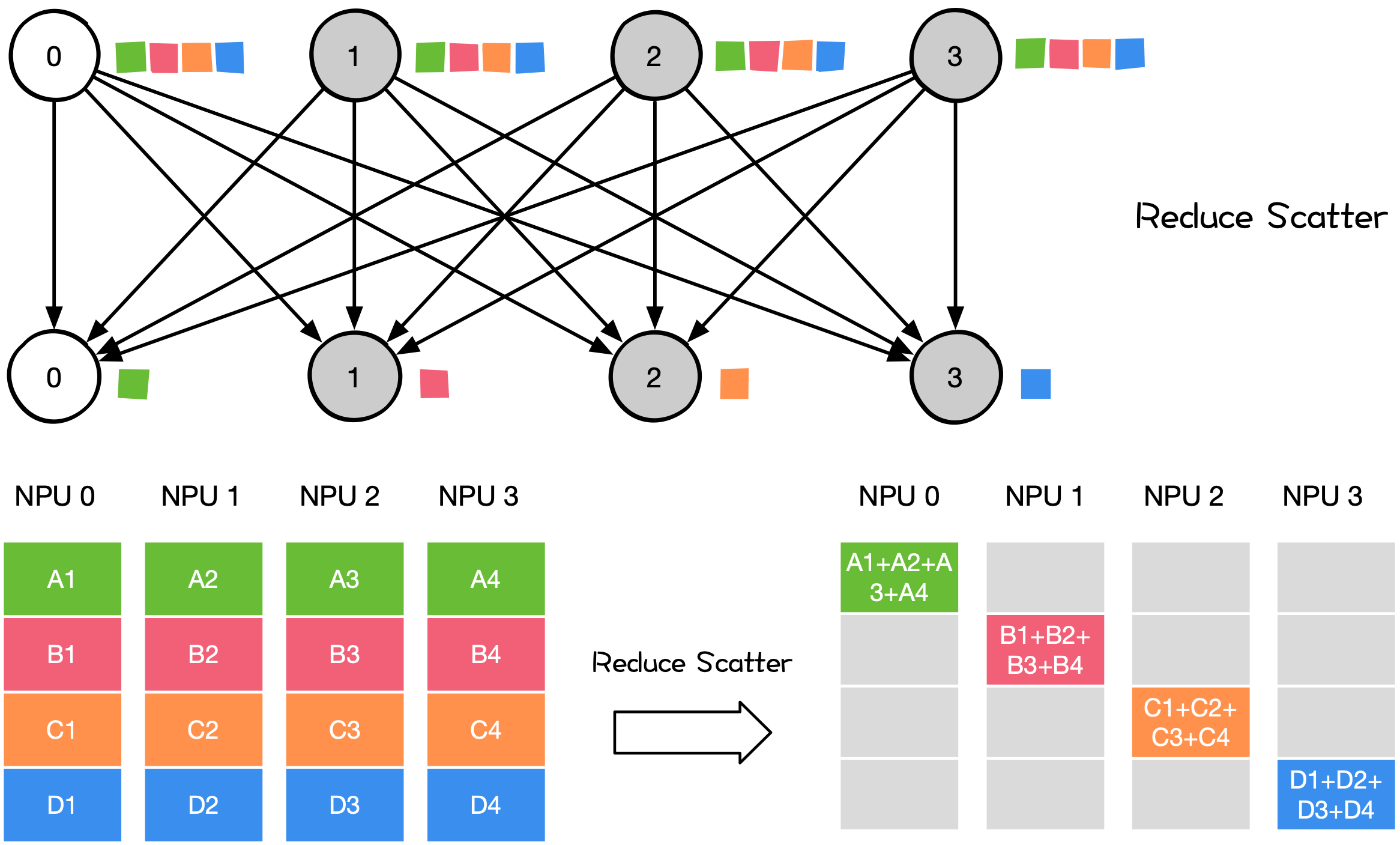
大模型训练和推理过程中,涉及到 Reduce-Scatter 的操作有:
数据并行 DP 中使用的 All-Reduce
All-Reduce 可分解为 Reduce-Scatter 和 All-Gather 两个阶段;
模型并行 MP 前向 All-Gather 后的反向计算 Reduce-Scatter;
All2All#
All to All 操作是对 All-Gather 的扩展,但不同的节点向某一节点收集到的数据是不同的。
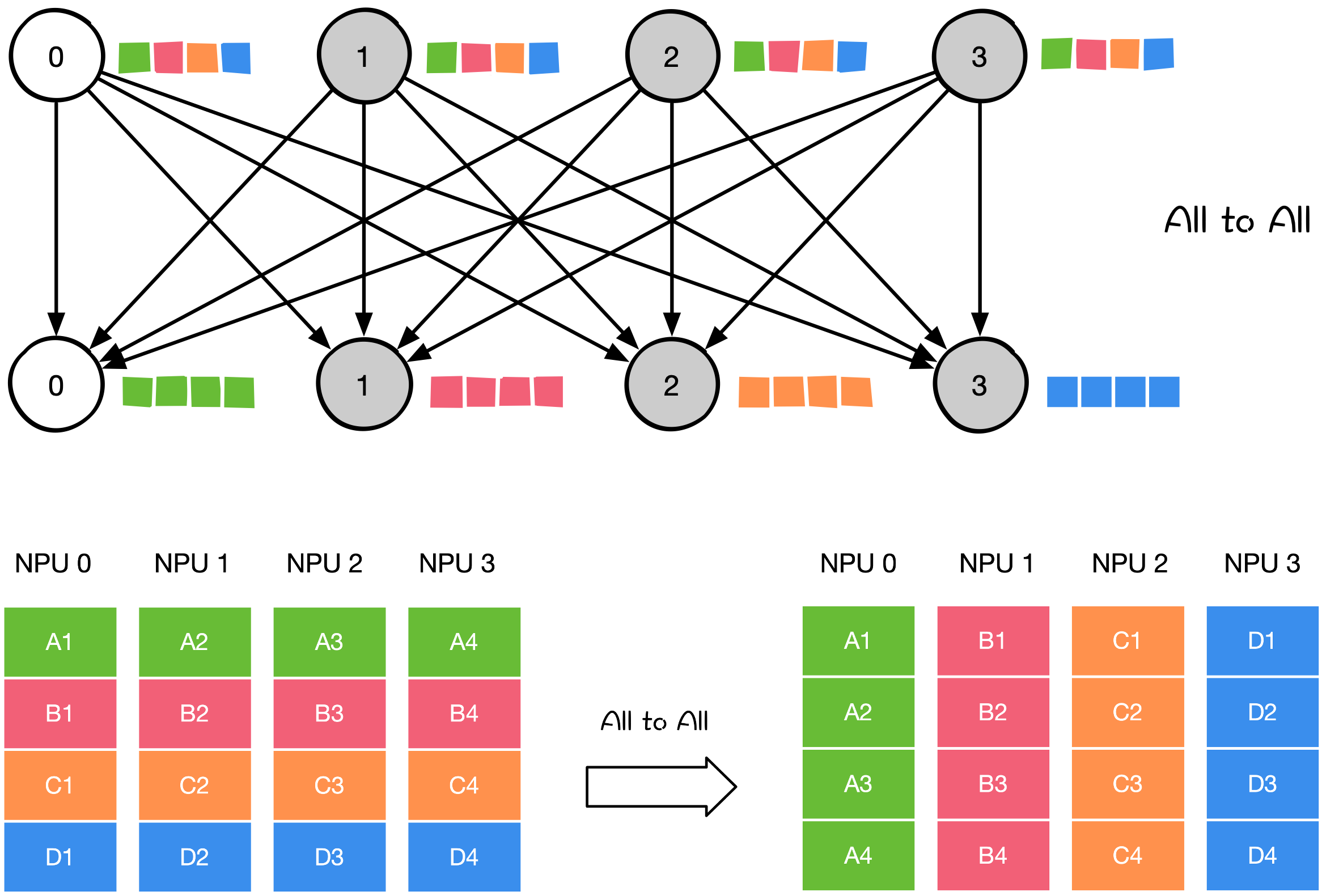
大模型训练和推理过程中,涉及到 All2All 的操作有:
应用于模型并行中的 TP/SP/EP;
模型并行里的矩阵转置;
DP 到模型并行的矩阵转置;
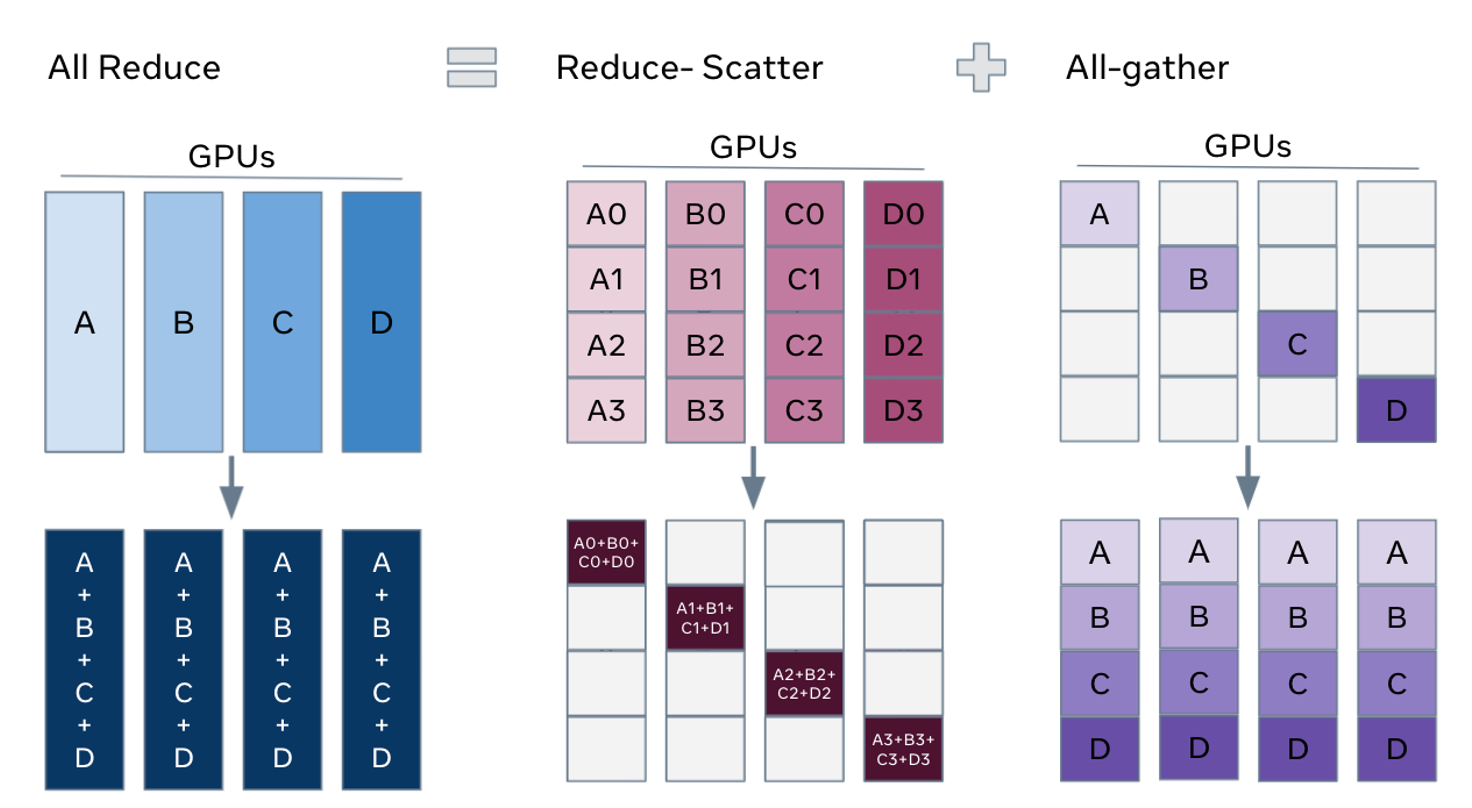
通信操作分解 All-Reduce#
在前三个小节中我们提到了通信操作之间有关联,其可以分解为多个通信操作。本小节将简要介绍 All-Reduce 的分解。
!!!!!!!!!!!!!!!!! 不要完全按照视频来,视频只是导读,而且业界变化很快,需要根据内容来展开深入,例如 all reduce 的拆解就在这里展开就可以了,比较自然。
如下图所示,All-Reduce 可以由 Reduce-Scatter 和 All-Gather 两个操作组合完成。在 Reduce-Scatter 操作完成后,每个 Rank 中规约了所有 Rank 中一个部分的结果。在 All-Gather 操作中,每个 Rank 将其数据广播到所有 Rank,最终每个 Rank 都获得所有 Rank 规约的结果。
典型通讯模型#
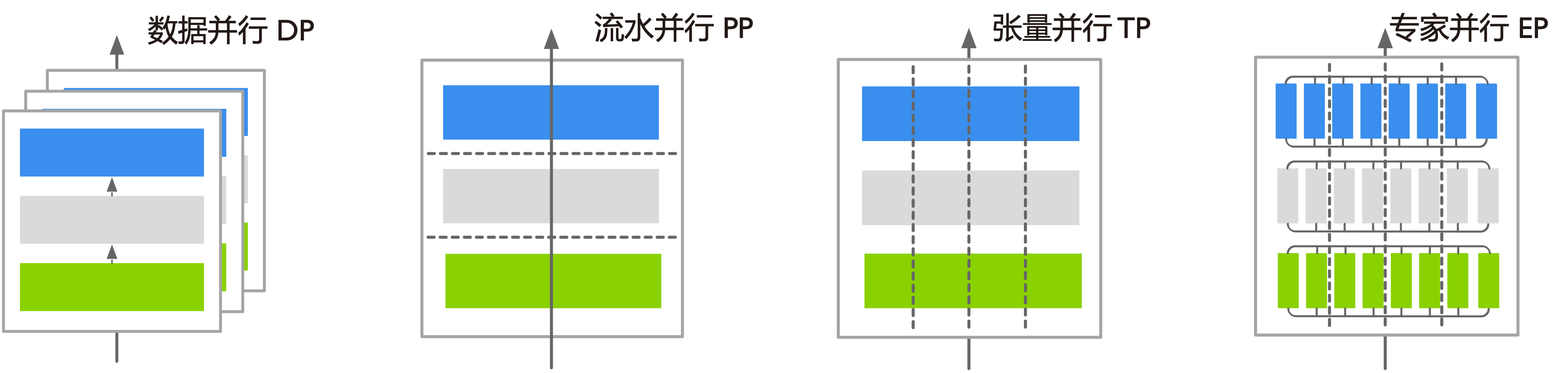
下表展示了典型并行类型、涉及的主要通信操作、节点规模及数据量。
类型 |
通信操作 |
节点规模 |
数据量 |
备注 |
|---|---|---|---|---|
数据并行 DP |
All-Reduce、Broadcast |
~理论无限 |
~GB |
节点规模增长会受线性度影响 |
张量并行 TP |
All-Reduce、All-Gather、Reduce-Scatter |
2 / 4 / 8 Rank |
MB~GB |
计算通信可隐藏,节点内进行,不宜跨节点 |
流水并行 PP |
Send、Recv |
2 Rank |
~MB |
通过多 Micro Batch 实现计算通信可隐藏 |
序列并行 SP |
All-Reduce、All-Gather、Reduce-Scatter |
~理论无限 |
MB~GB |
计算通信可隐藏 |
专家并行 EP |
All2All |
~理论无限 |
~MB |
计算通信串行,不可隐藏 |
总结与思考#
在学习了本章内容后,我们对集合通信原语有了更加深入的理解:
了解集合式通信的 3 种不同方式
了解一对多 Scatter/Broadcast,多对一 Gather/Reduce,多对多具体方式
了解多对多可以由一对多和多对一的方式组合