05.通信域与 PyTorch 实现#
作者:SingularityKChen & 陈彦伯
本章的前四节介绍了集合通信的基本概念并介绍了一些常用通信原语和通信算法。在整个 AI 系统中,通信算法与通信原语位于较高抽象层级,主要面向分布式训练算法与 AI 模型设计者。在此之下,通信域(Communicator) 是一个重要的中间层次。它屏蔽了底层通信链路的硬件细节差异、集中维护集合通信的元信息,为上层算法实现和调用提供了诸多便利。本节首先从一个较高的视角概述通信域的原理与概念,之后以 PyTorch 为例了解其代码实现。
通信域#
通信的本质是数据在处理单元之间的传输。我们不妨将 AI 系统类比为一个“污水处理厂”:如果输入数据是“污水”,那么服务器就是处理水的“工厂”,而计算单元(如 CPU、GPU 和 NPU 等)就是工厂中的“净化器”。多个工厂与净化器彼此之间通过水管相连,具备相应的拓扑结构,我们以此类比集合通信中的通信链路。多个工厂和净化器的同时作业就类似并行计算,只不过服务器和计算单元不像人一样懂得变通,他们需要清晰的指令,包括数据的处理方式与收发去向等。
基于上述类比,我们来看几个有关集合通信与通信域的重要概念。
节点(node) 和 rank:集合通信中一般将一台服务器抽象为一个节点。一个节点下可能包含多个 rank,即服务器中搭载的多个计算单元。在并行计算任务中,每个节点和 rank 都会被赋予一个唯一的全局 ID,这是为了方便统一地指定数据的处理方式与收发去向。在每个节点中, ranks 还会被赋予一个 local ID,这是为了方便一些需要节点内互传的通信算法,如 Reduce、Gather 等。
进程(process) 与进程组(group):注意,进程与 ranks 之间并不是一一对应的关系。在复杂的 AI 训推任务中,计算单元会被动态地分配
上下文:由于
拓扑(topology):即节点、计算单元之间的链路信息。与上下文信息一样,通信域的拓扑信息一般由通信后端统一管理。
不了解集合通信的读者可能会提出一个很自然的问题:为什么通信域里要维护这么多信息? 这是因为当设备数量、网络拓扑等条件不同时,即便是同一个通信算法的具体实现也是不一样的。换句话说,通信域中所维护的信息是为了让上层封装(如下文会讲到的 torch.distributed)得以自动选择合适的算法实现。
通信域(Communicator)
通信域、进程、进程组与 Rank 的关系;
模型并行/数据并行/流水并行下的通信域划分;
PyTorch 如何通过
torch.distributed调用 P2P 与集合通信原语;训练时“计算–通信”并行(overlap)的底层机制。
通信域、Rank、进程和进程组关系#
Remark(关于 MPI):集合通讯中很多术语来自 MPI 标准,但之前的文章和 ppt 中好像并没有展开谈这个点。关于 MPI 的讨论是必要的吗?需要设计多少、多深?我觉得关于 MPI 的讨论对文章完整性有好处,但可能有些跑题。
通信域是各大集合通讯库(如 NCCL、XCCLs)中的重要概念,也是 MPI 标准与深度学习分布式系统的核心抽象。关于通信域的一些概念和定义在不同语境下有微妙的区别。为严谨起见,如无特殊说明,本文的叙述均基于 MPI 中的定义。下图简述了通信域与 MPI 的关系。

MPI 5.0 官方文档中描述通信域的作用为 管理一组(group)互相通信的进程(process) 并 维护进程间的上下文(context)信息。其中,进程由 OS 统一管理,每个进程会被分配一个唯一的 PID。在通信域内,进程以 MIMD 的形式执行各自的代码;进程间通过通信原语进行通信。上下文是 MPI 为隔离通信、避免干扰而设计的特殊机制,一般体现为通信域的唯一标识。在大模型训推系统中,通信域的实现在框架层之下,一般由 通信后端(backend) 提供。例如在 PyTorch 中,通信域的概念由 进程组(process group) 抽象表示,但其具体实现依赖 NCCL、HCCL、Gloo、MPI 等后端通信库提供的接口。
为简单起见,本文会在不引发混淆的情况下刻意地 不 区分通信域与其对应的进程组。例如我们定义通信域的 size 为其中所包含进程的数量,严格地说应是其所对应进程组的性质。初始化时,通信域中的每个进程都会被赋予一个独立的整数 rank ID(从 0 到 size-1 中选取)。注意,在一些集合通信库(如 NCCL)中,rank ID 一般对应到设备,而非像 MPI 一样对应到进程。按照定义,集合通信中的进程与设备的概念并不是一一对应的:一个进程可以包含多个设备,一个设备也可以被多个进程共享。概念上的细微差异实则反映出 MPI 标准与大模型训推系统在设计思路上的本质区别,读者需要在学习与实践中逐渐体会。
MPI 与大模型训推系统的另一个差异之处在于 节点(node) 与 拓扑(topology) 的定义。首先,MPI 在关于通信域的定义中并没有明确节点的概念。大模型训推系统其实借用了计算机网络与分布式计算中的观点,将通信网络分为节点与链接这两个关键组成部分。其中,计算机网络中的节点包括分发点(如路由器)与通信终点(如计算机),但在在大模型训推的语境下,节点一般指代具有一个或多个处理单元的服务器。节点间用于传输数据的介质被称为链接,包括物理链接与逻辑链接,对应的拓扑结构被称为物理拓扑与逻辑拓扑。MPI 中的拓扑概念与计算机网络中节点间的逻辑拓扑类似。具体来说,MPI 将通信域中的进程间的 虚拟拓扑(virtual topology) 定义为了一个包含进程本身与进程之间的通信链路的图结构。MPI 的拓扑图是非强制的:即便两个进程在拓扑图中没有显式的链接,通信仍然可以进行(MPI 会认为这条边被忽略了,而非不存在)。MPI 的虚拟拓扑旨在为上层通信原语和通信算法提供更简单、更易读的代码实现。
通信域在并行计算中的应用#
Remark:这一段我看之前也没有提修改意见,而且相对独立,就先放这里没咋动。先写后面的。
下图示意将一个多层前馈网络沿层内与层间两个方向切分:蓝色与黄色区域形成层内切分的 张量并行(tensor parallel, TP);A/C/E/G 之间形成 流水并行(pipeline parallel, PP)。
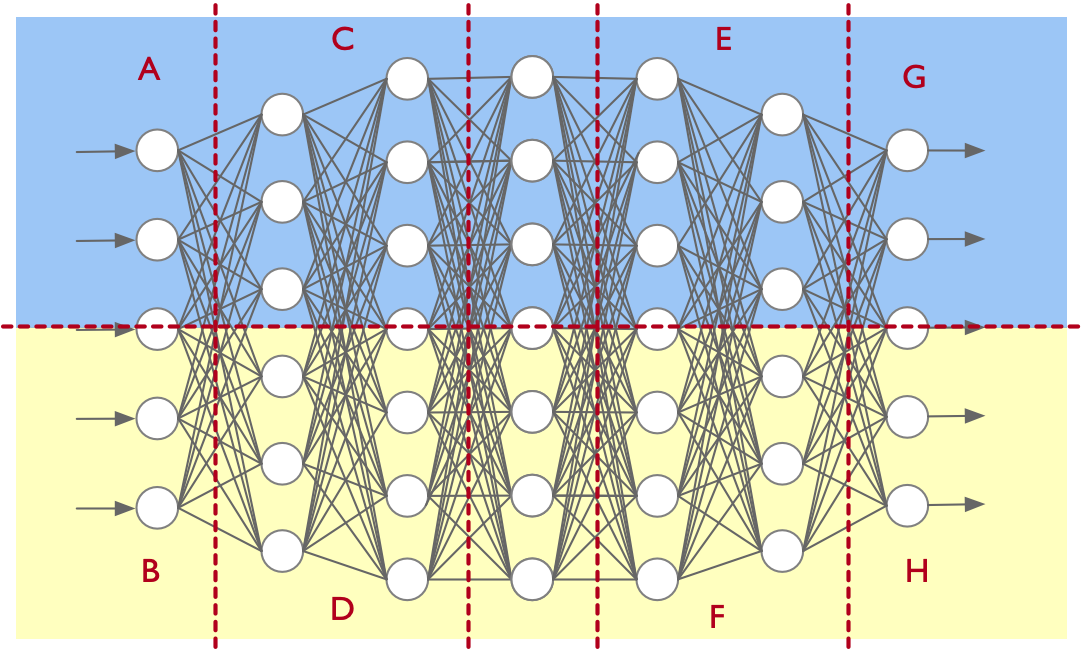
在TP 通信域中, Node 0 中 Rank 0 (NPU 0)和 Rank 1 (NPU 1) 各自处于不同进程,二者在同一个通信域,组成一个进程组。
在PP 通信域中,NPU 0/4/8/12 形成一个进程组。
在数据并行(DP)/模型并行(MP) 时,还会额外形成跨节点的通信域。对应示意如下两图。
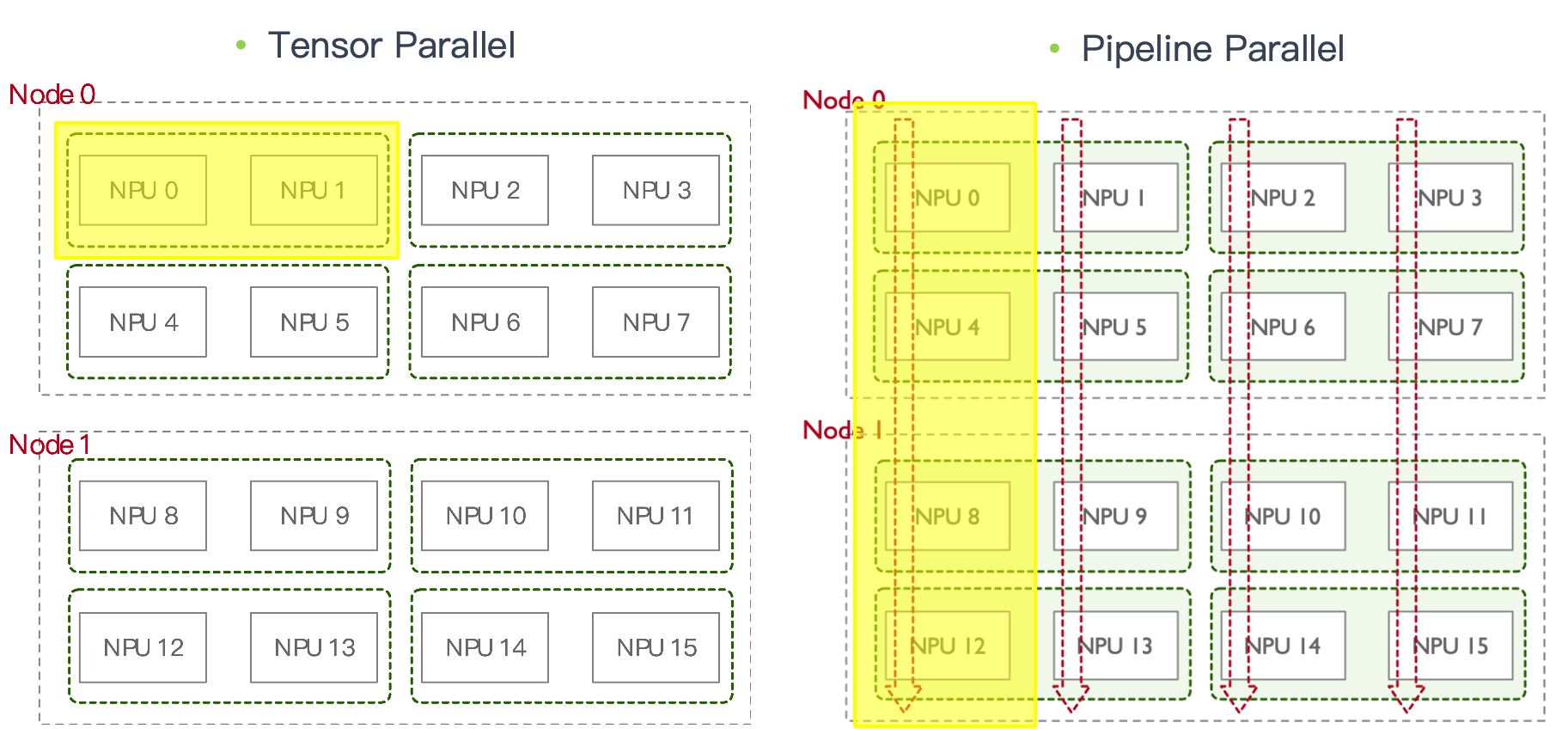
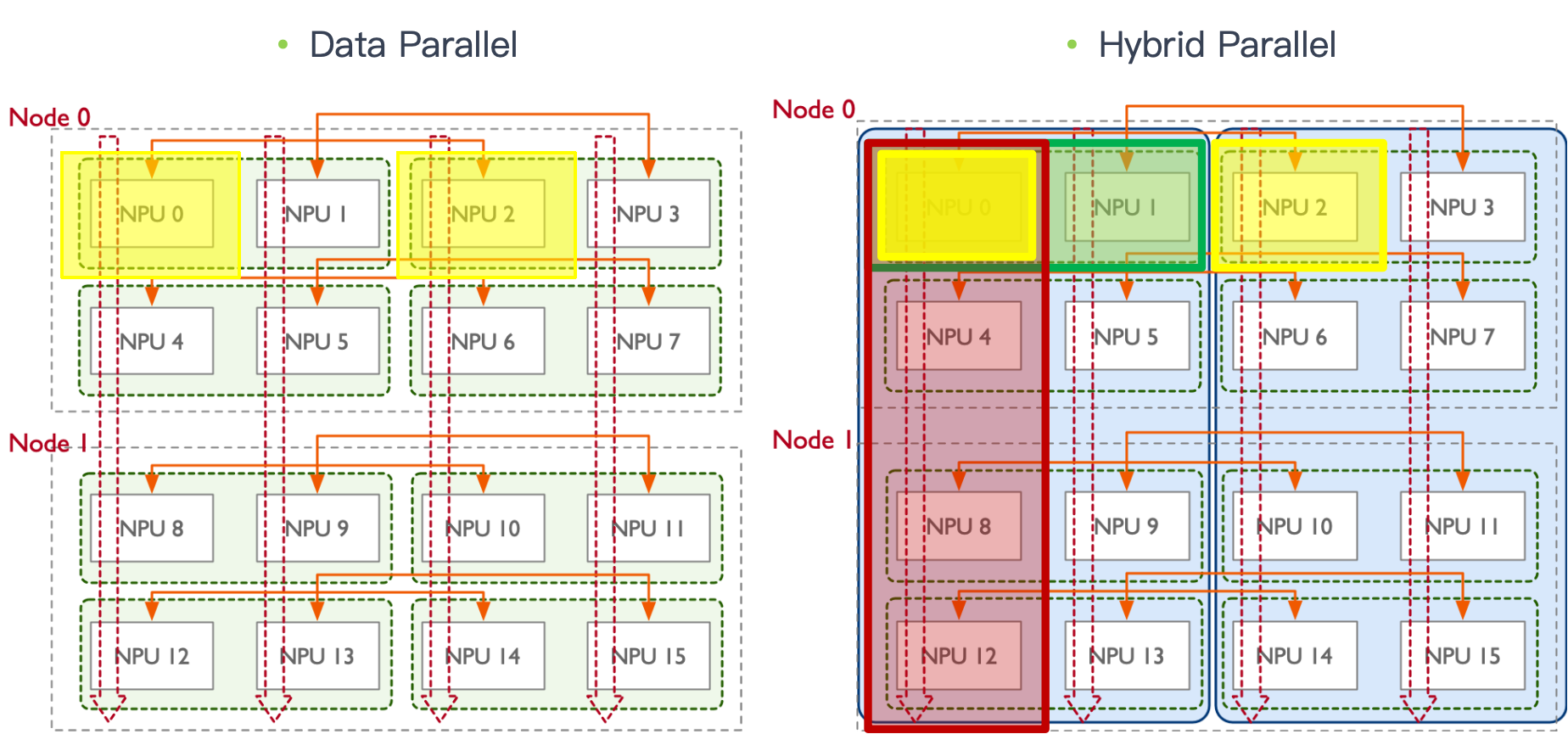
由此,一个 rank(例如 NPU0 对应的进程)常常同时隶属于多个通信域:
与 NPU1 组成 TP 域;
与 NPU2 组成 DP 域;
与 NPU4/8/12 组成 PP 域。 这也是后续做 overlap 时需要仔细处理流与依赖的原因之一。
通信域的 PyTorch 实现#
!!!!!!!!!!!!!!!! 这里是本篇的重点,应该自己去看看 PyTorch 的通信是怎么实现的,一定一定要自己去深入看代码,深入技术,不要在视频的表面,自己要做的比视频要更加深入
PyTorch 的分布式能力位于 torch.distributed (一般缩写为 dist)模块中。目前最新版本(v2.9.0)的 dist 主要包含 并行化 API(parallelism APIs) 和 通信 API(communications APIs) 两部分 API。其中并行化 API 涵盖了 DDP、FSDP、TP、PP 等功能,属于较为高级的封装,而通信 API 则更关注底层通信能力。~~下图展示了 dist 模块的整体架构与调用路径。~~
Remark(本文的主题?): 本章后半部分感觉怪怪的,我理解
distributed.py(对应nn\parallel\distributed.py)应该是实现DDP对应的功能吧?但我们这章的主题不是通信域吗?
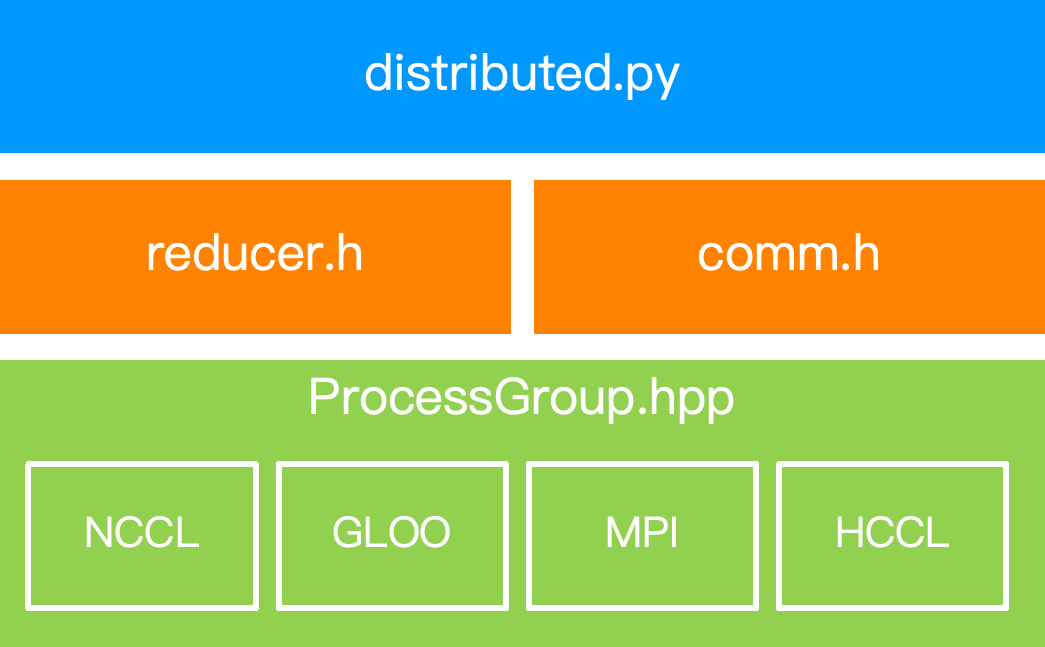
本节我们将主要关注 dist 的通信 API 部分并围绕通信域管理这一主题展开。dist 的能力主要由 C10D 库(即 C10 Distributed 的缩写,基于 C++ 代码)实现,提供了直接传输 torch.Tensor 的能力,而不像 FastAPI 或 gRPC 那样需要类型转换。dist 的语法与 MPI 非常类似。如前文所述,dist 使用“进程组”这一概念来表示通信域,并负责管理进程组的元信息。注意,dist 本身并不提供多进程启动的能力,用户需要借助 torch.multiprocessing 或其他工具(如 torchrun)来启动多进程环境。
通信域的初始化#
PyTorch 通过 dist.init_process_group 函数来初始化通信域。在通信域的初始化阶段,dist 需要进行进程的 发现、握手与同步 这三个步骤。根据进程发现的方式不同,dist 支持多种初始化方法(init_method),其中最常用的是基于环境变量的初始化,也即不指定 init_method 的默认方法。此外,用户还可以基于 URL 或使用 store 参数传入自定义进程发现方法。进程的握手由通信后端(如 NCCL、Gloo 等)负责完成,PyTorch 层没有提供具体接口。进程同步则则通过 dist.barrier 函数(或一些特殊对象——如 dist.Work—— 的 .wait() 方法)实现。下面的代码以基于环境变量的初始方法与 backend='nccl'为例,展示了如何初始化一个单机 8 卡 8 进程通信域。
Remark: 我自己只用过默认 init_method,其他几种方式常用吗?如果不常用我就不展开讲了。
import os
import torch
import torch.distributed as dist
from datetime import timedelta
# 查看环境变量
print(os.environ['RANK'])
print(os.environ['WORLD_SIZE'])
print(os.environ['MASTER_ADDR'])
print(os.environ['MASTER_PORT'])
dist.init_process_group(backend='nccl')
假设上述代码命名为 init_dist.py,则可以通过如下命令初始化通信域:
torchrun --nproc-per-node 8 --nnodes 1 --node_rank 0 --master-addr "localhost" --master-port 29500 init_dist.py
基于环境变量的初始化方法需要用户在启动多进程环境时,预先设置好 RANK、WORLD_SIZE、MASTER_ADDR、MASTER_PORT 等环境变量。其中 MASTER_ADDR 与 MASTER_PORT 用于指定主节点的地址与端口,WORLD_SIZE 表示进程数量。这三个环境变量在多个进程中必须相同。RANK 表示当前进程的 rank ID 与通信域的规模,不同进程需要设置不同的 RANK。在实际使用中,建议使用 torchrun 指令来自动拉起并配置进程及其对应参数,用户只需指定 -n/--nnodes、--node_rank、--master_addr 与 --master_port 即可。读者可以运行上述代码并观察打印出来的结果。
dist 支持 点对点(peer-to-peer, P2P) 与 集合通信(collective communication, CC) 两类通信模式。其中:
P2P 通信是进程之间一对一通信,发送方被称为源进程(source, 简称 src),接收方被称为目的进程(destination, 简称 dst)。P2P 通信的主要功能为发送与接受向量,由
dist.send和dist.recv语义,用于任务间通信;集合通信则提供了 scatter/broadcast/gather/reduce/all reduce/all gather 等通信操作。集合通信:
其中
Remark:这一部分我也不是很懂,C的部分要写多深?有点太底层了。 ——陈彦伯
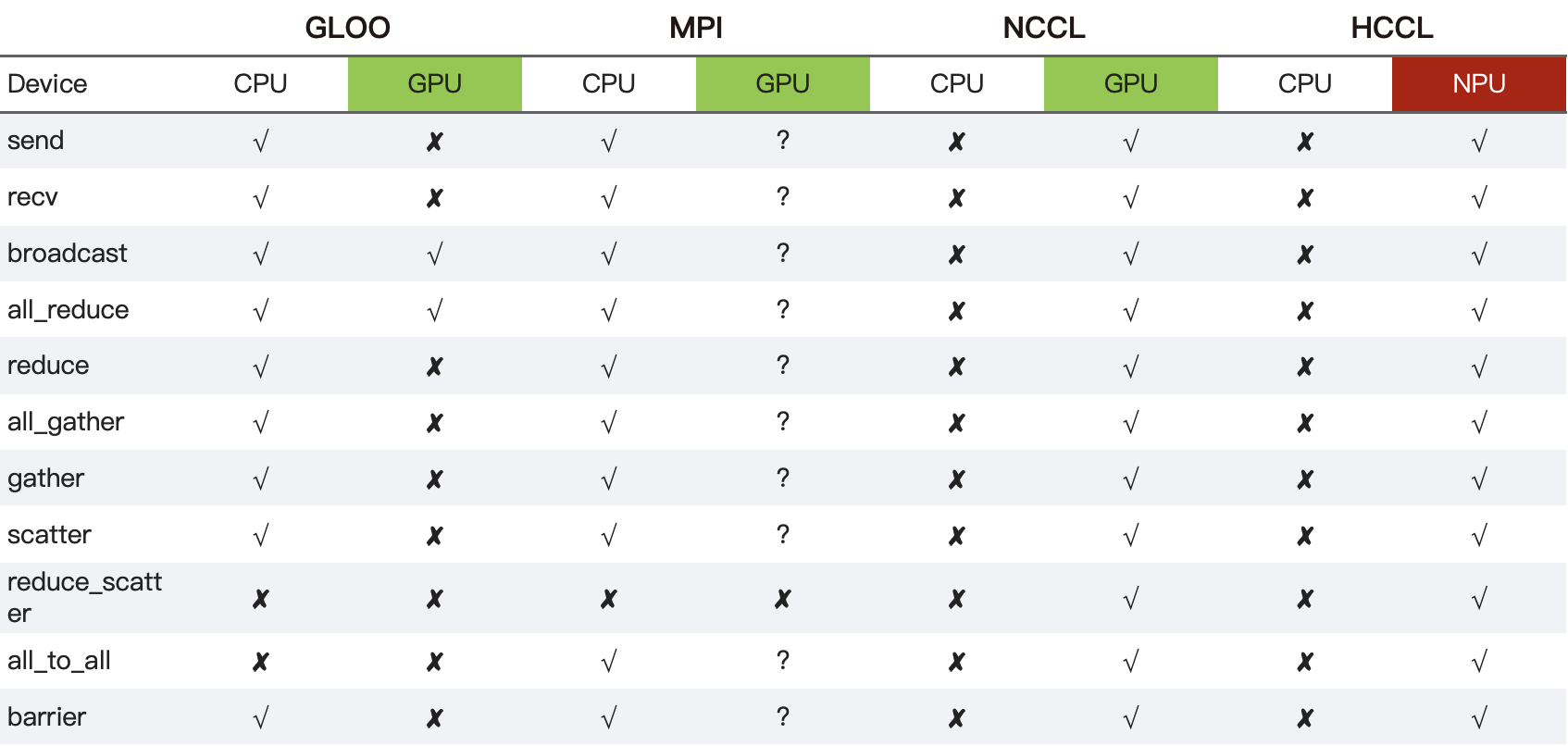
后端通信库的能力差异#
Gloo(CPU):提供基础集合通信与 P2P,用于通用 CPU 环境;
MPI(CPU/GPU):语义覆盖较全;
NCCL(GPU)/HCCL(NPU):面向深度学习高带宽低延迟互联,重点覆盖 AllReduce / AllGather / ReduceScatter / AllToAll / Broadcast / Barrier 等训练常用原语。
P2P Communication 操作#
!!!!!!!!!!!!!!!! 代码不要截图,插入代码,然后解读
初始化:在每个进程中调用
torch.distributed.init_process_group指定后端、rank与world_size,对分布式模块进行初始化。通信逻辑:按
rank_id分支业务;dist.send()/dist.recv()为同步版本,isend()/irecv()为异步版本。任务启动:使用
torch.multiprocessing启动多进程;set_start_method('spawn')仅继承必要资源,便于跨进程安全初始化。
PyTorch 的“计算–通信”并行#
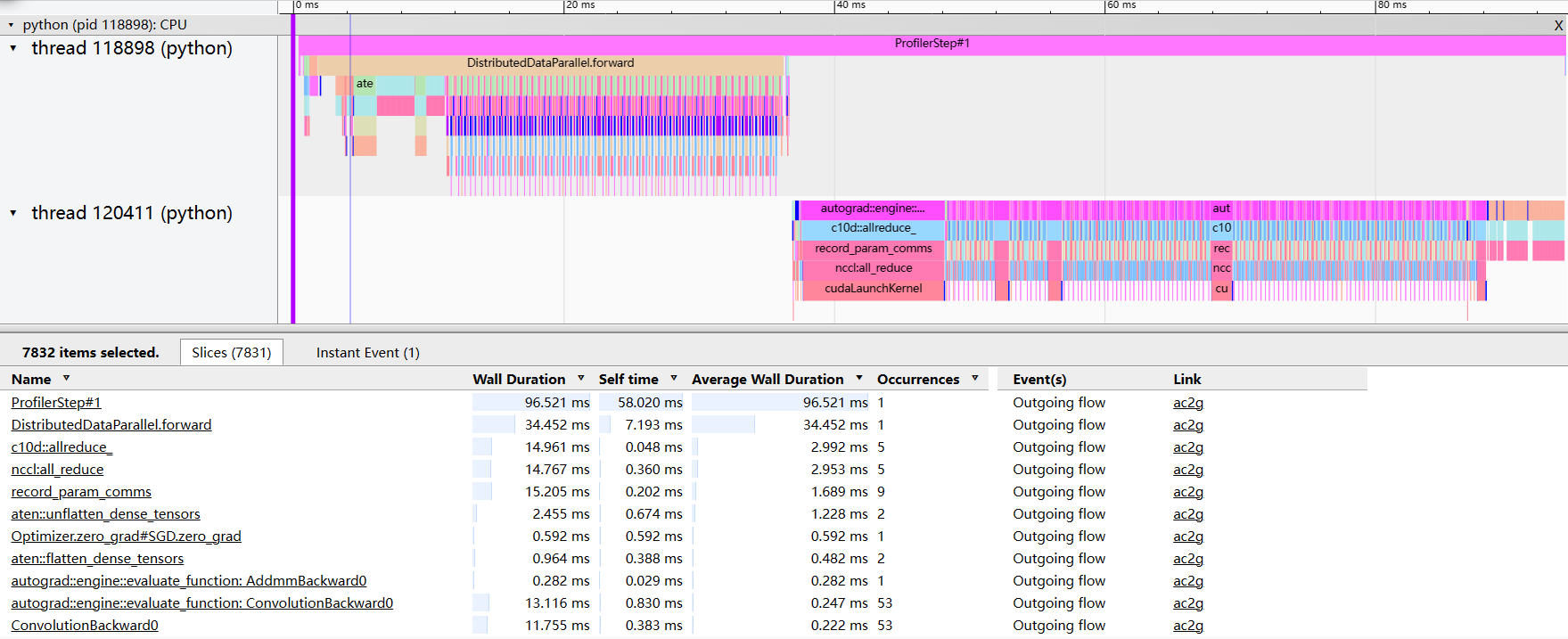
PyTorch 计算与通信并行的分析主要依赖一些 profile 工具。下面展示了一个 profile 的截图,其中可以看到每个时间点有哪些操作正在进行。
Stream / Event 基础#
Stream:设备侧的异步命令队列;PyTorch 的内存池与 Stream 绑定,能把数据搬运与算子执行并行化,提高吞吐。
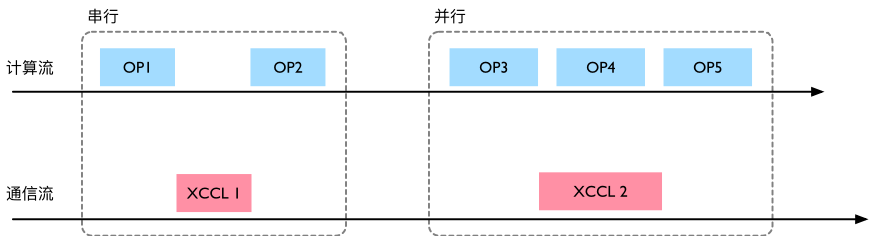
Event:轻量级的时序/同步原语,可在 Stream 中记录标记点用于等待或测时。 PyTorch 通信与计算并行,主要通过 Stream(并行能力)与 Event(时序控制)这两个提供的底层能力来实现。
如下图所示,串行执行时是 OP1→XCCL1→OP2;并行化后,OP3 结束即可同时下发 XCCL2,计算流继续执行 OP4。
计算流之间的同步#
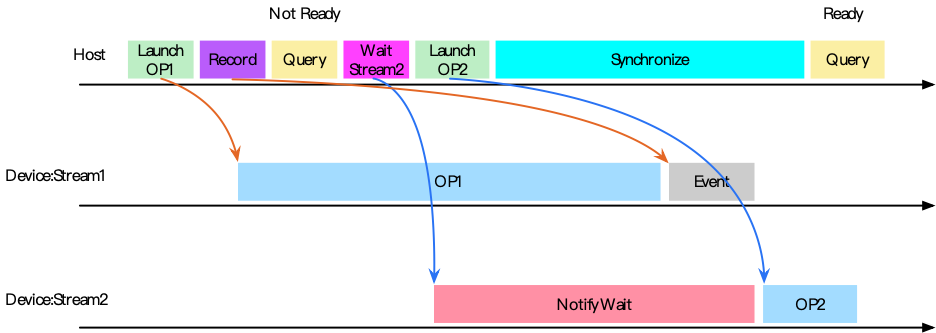
Host 下发与 Device 执行是异步的:先 Record event,再在目标 Stream 上 Wait;必要时 Host 侧 synchronize() 阻塞直到 event 完成。下图给出了典型的时序与 Query 的 ready/not-ready 状态变化。
计算流与通信流的同步与内存池归属#
!!!!!!!!!!!!!!!! 你真的懂了吗?
在 ProcessGroupXCCL 中,集合通信接口会经由 ProcessGroupXCCL::collective() 把实际的 XCCL 调用 FN 下发到 通信流(xcclStreams)。如下图所示,如果 OP1 的输出 Tensor 仍归属于计算流的内存池,会出现“OP1 写、XCCL1 读”的潜在竞争,需要在两条流之间建立事件依赖;需要用于通信的 Tensor,其内存应由对应 Stream 的内存池管理。
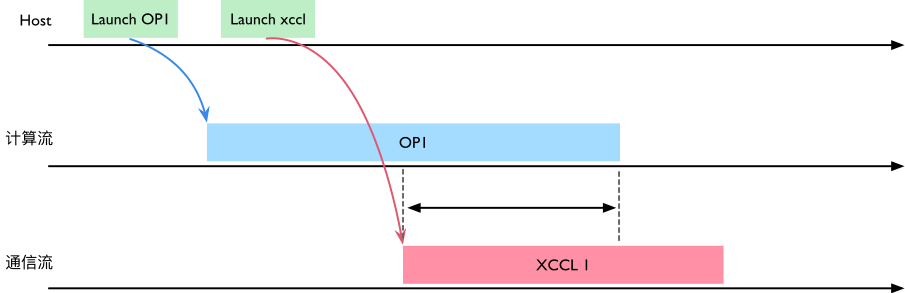
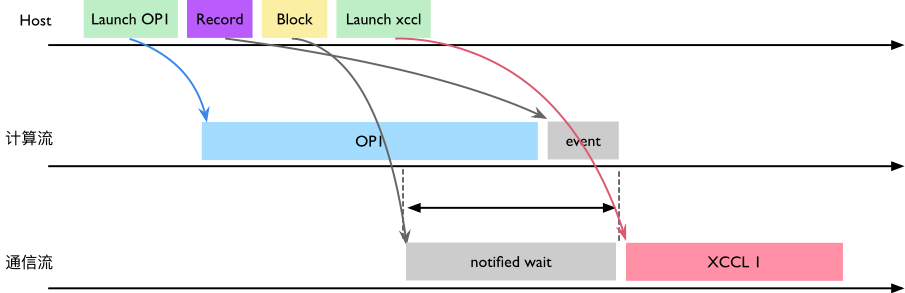
为解决上述异步问题,collective() 内部通过 syncStream():在计算流上 Record event,并在通信流上执行 notify/wait,确保“先写后读”,消除并发读写问题。其时序图如下。
反向场景(通信→计算)则由 work.wait() 完成:WorkXCCL::synchronizeStreams() 在需要处进行 block,并依赖于通信流上 xcclEndEvents_ 记录的事件来完成跨流同步。
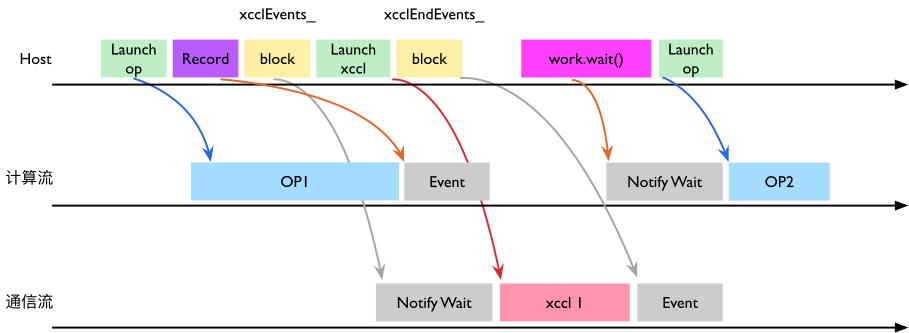
小结:解耦计算与通信、并通过事件把两者“正确且尽早”地拼起来,是大模型训练中提升 MFU 的关键路径;这也是各类分布式加速库(Megatron-LM/DeepSpeed/ColossalAI 等)在框架层面做策略优化与异步调度的原因。
总结与思考#
通信域—进程—进程组—Rank:一对多映射,同一进程可加入多个通信域并行工作。
多维并行对应多个通信域:TP/PP/DP/MP 交错存在,单个 rank 可能在多个域中承担不同职责。
PyTorch 分布式分层:DDP(前端)→ ProcessGroup(抽象)→ NCCL/HCCL/Gloo/MPI(后端)。
集合通信后端能力差异:不同后端在集合通信/设备支持上各有侧重,要结合硬件与网络选择。
PyTorch 计算–通信 overlap:通过 Stream/Event,用
syncStream()与work.wait()正确编排跨流依赖,减少串行等待。
本节视频#
参考资料#
本文中所涉及的概念整合自维基百科以及一些经典教材,技术细节则主要参考 PyTorch 官方文档与源码实现。读者可结合以下资料深入学习。
https://en.wikipedia.org/wiki/NVLink#Service_software_and_programming
https://en.wikipedia.org/wiki/Collective_operation