07.大模型参数设置#
Author by: 张志达
大模型参数说明#
我们常见的大模型的参数量级, 主要受如下参数的影响,
Dense模型#
Dense模型, 即每次推理时激活的参数为100%的模型, 常见的模型以Qwen3-32B等为代表。 影响最终模型参数量级如下:
vocab_size#
表示当前模型中 tokenizer模块能识别的唯一token数量。比如Qwen3系列为vocab_size 为 151936, 表示Qwen3系列模型的词汇表包含约15.2万个唯一token
模型的词汇表的个数与 模型embedding层的shape相关, embedding层的shape为(vocab_size, hidden_size), embedding层就是一个map逻辑,根据具体的token,通过tokenizer 找到对应的索引, 再到embedding 查找出对应的向量
head_dim & num_attention_heads#
见前文, 在进行attention计算时, 会进行多头并行计算 遂会将hidden_size 拆成 num_attention_heads * head_dim。实际 使用时的步骤如下:
# 1. hidden_size乘 wq,wk wv 获取 qkv矩阵
qkv = qkv_proj(hidden_states)
q, k, v = qkv.split([q_size, kv_size, kv_size], dim=-1)
# 2. 将qkv的hidden_size为 num_heads * head_dim
q = q_norm(q.view(-1, num_attention_heads, head_dim))
k = k_norm(k.view(-1, num_kv_heads, head_dim))
v = v.view(-1, num_kv_heads, head_dim)
# 3. 应用位置编码
q,k = rotary_emb(positions, q, k)
# 4. 维度转换, 从(B,S,H,d) ->(B, H, S, d),方便后续做并行的多头计算
q = q.permute(0, 2, 1, 3) # (B, H, S, d)
k = k.permute(0, 2, 1, 3) # (B, H, S, d)
v = v.permute(0, 2, 1, 3) # (B, H, S, d)
intermediate_size#
前馈神经网络(FFN)中间层的维度大小 FFN是Transformer中的一个关键组件,通常包含两个线性层和激活函数。intermediate size是第一个线性层的输出维度。
举例:Qwen3-0.6B的intermediate size为3072,表示FFN的中间层有3072个神经元
num_kv_heads#
key和value 的头数 在GQA的机制中, KV头数少于注意力的头数, 用于减少计算量。
如在Qwen3-0.6B的模型中, num_key_value_heads的值为8, num_attention_heads的值为16。表示模型会将16个注意力头分组为8个组, 每个组共享相同的Key和Value。
以Qwen3举例如下:
Model |
head_dim |
hidden_act |
hidden_size |
intermediate_size |
max_position_embeddings |
max window layers |
attention heads |
num_hidden_layers |
num_kv_heads |
vocab_size |
|---|---|---|---|---|---|---|---|---|---|---|
Qwen3-0.6B |
128 |
silu |
1024 |
3072 |
40960 |
28 |
16 |
28 |
8 |
151936 |
Qwen3-1.7B |
128 |
silu |
2048 |
6144 |
40960 |
28 |
16 |
28 |
8 |
151936 |
Qwen3-4B |
128 |
silu |
2560 |
9728 |
40960 |
36 |
32 |
36 |
8 |
151936 |
Qwen3-8B |
128 |
silu |
4096 |
12288 |
40960 |
36 |
32 |
36 |
8 |
151936 |
Qwen3-14B |
128 |
silu |
5120 |
17408 |
40960 |
40 |
40 |
40 |
8 |
151936 |
Qwen3-32B |
128 |
silu |
5120 |
25600 |
40960 |
64 |
64 |
64 |
8 |
151936 |
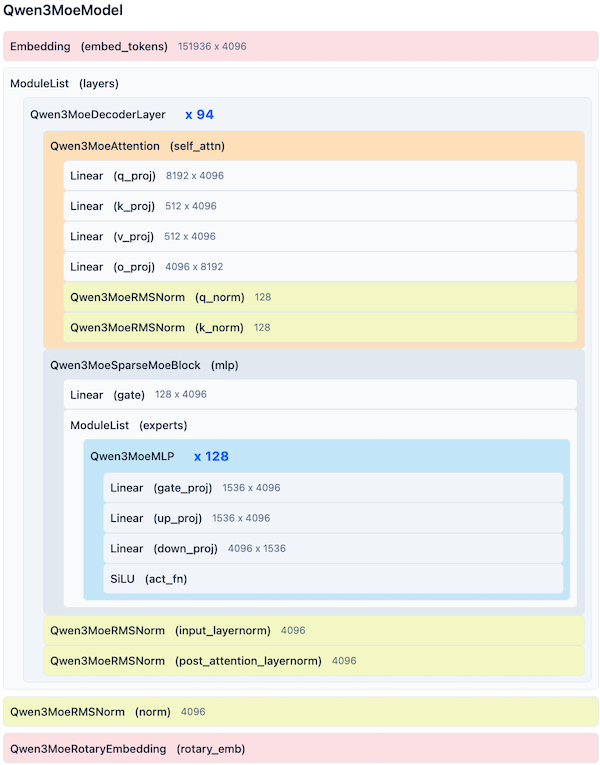
Qwen3-32B 结构示意
MOE 模型#
MOE模型, 即每次推理时激活的参数为局部参数, 常见的模型以Deepseek-V3,KIMI-K2,Qwen3-235B-A22B等为代表。 影响最终模型参数量级如下:
moe_intermediate_size#
MoE(混合专家)中间层的维度大小 在MoE架构中,每个专家内部有一个中间层。moe intermediate size表示这个中间层的维度。例如,Qwen3-30B-A3B的moe intermediate size为768,表示每个专家的中间层有768个神经元。
num_experts#
每层中专家的总数 MoE架构中,每层包含多个专家,num experts表示每层的专家总数。例如,Qwen3-30B-A3B有128个专家,表示每层有128个不同的专家网络。
n_shared_experts#
共享专家数量 在MoE架构中,有些专家是所有token共享的,n_shared_experts表示共享专家的数量。
model |
head_dim |
hidden_act |
hidden_size |
intermediate_size |
max position embeddings |
max window_layers |
moe_intermediate_size |
attention_heads |
num_experts |
num_experts_per_token |
n_shared_experts |
num_hidden_layers |
num_kv_heads |
vocab_size |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Qwen3-30B-A3B |
128 |
silu |
2048 |
6144 |
40960 |
48 |
768 |
32 |
128 |
8 |
/ |
48 |
4 |
151936 |
Qwen3-235B-A22B |
128 |
silu |
4096 |
12288 |
40960 |
94 |
1536 |
64 |
128 |
8 |
/ |
94 |
4 |
2151936 |
DeepSeek-V2-236B |
128 |
silu |
5120 |
12288 |
163840 |
/ |
1536 |
128 |
160 |
6 |
2 |
60 |
128 |
102400 |
DeepSeek-V3-671B |
128 |
silu |
7168 |
18432 |
163840 |
/ |
2048 |
128 |
256 |
8 |
1 |
61 |
128 |
129280 |
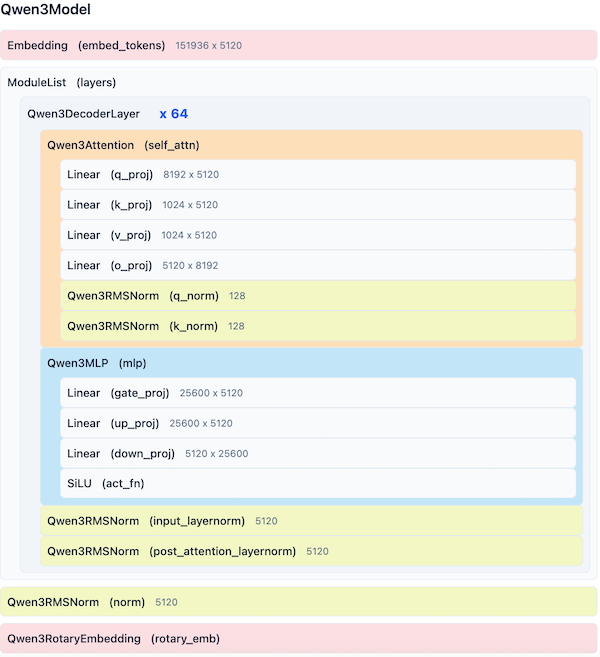
Qwen3-235B-A22B 结构示意