09. 流水并行衍生算法(DONE)#
Author by:高亮
在大模型训练中,并行技术是突破硬件算力与显存瓶颈的核心手段,而流水并行凭借对模型层的纵向切分能力,成为大规模训练的关键支柱。传统 GPipe 虽通过 micro-batch(微批)切分摊薄气泡,但面临尾部气泡先天存在、激活显存随 micro-batch 数量(记为 m)线性增长的难题;当 m 受硬件显存限制时,流水线深度增加反而会降低吞吐效率。
为突破这一困境,One-Forward-One-Backward(1F1B,即 PipeDream)调度方式应运而生:通过让 micro-batch 的反向计算尽早折返并与后续前向计算交错,将激活驻留时间从 \(O(m)\) 压缩至 \(O(p)\)(其中 \(p\) 为流水线深度,即切分后的 stage 数量),大幅降低显存压力。在此基础上,虚拟流水并行(Virtual Pipeline Parallelism,简称 VPP)、PipeDream-2BW、Zero-Bubble PP(简称 ZB-V)等衍生技术进一步优化气泡率与通信开销。本文将从原理出发,拆解这些主流流水并行技术的设计逻辑与优势,为大模型高效并行训练提供技术参考。
1. PipeDream 算法#
1.1 两段式问题#
先全前向、再全反向的“两段式”调度流水线技术,以朴素流水和 GPipe 为代表。
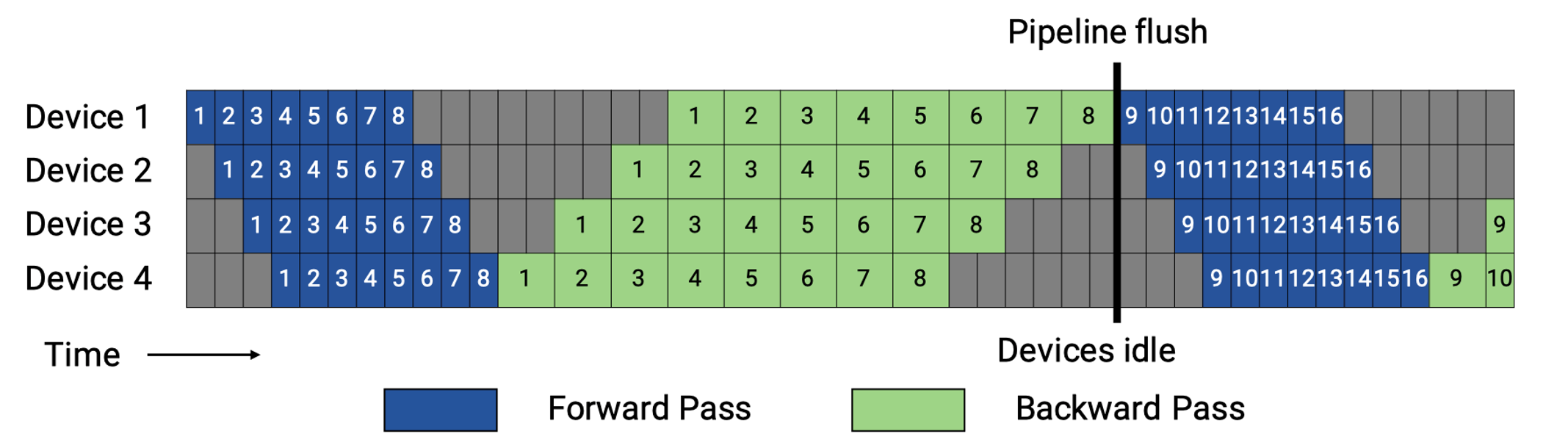
朴素流水相当于 \(m{=}1\)(即不切分 micro-batch),GPipe 则把 mini-batch 切成 \(m\) 个 micro-batch,并在前向、反向两个阶段内各自形成流水。两段式流水调度的核心问题在于由调度技术导致的流水气泡难以消除(warmup 灌满与 cooldown 排空阶段不可并行导致空闲),只能通过增大 \(m\) 摊薄;当 \(m\) 因硬件内存有限而受限时,即使加深流水线深度 \(p\),头尾气泡的相对占比也会上升,导致吞吐不增反降。此外,两段式流水调度还存在以下问题:
尾部气泡先天存在:由于前向、反向两个阶段被硬性分隔,反向计算无法与后续前向计算交错,流程收尾阶段(cooldown)的尾部气泡完全暴露,最多只能通过增大 \(m\) 来“摊薄”气泡占比。
通信-计算重叠受限:前向或反向阶段内部,可将激活/梯度传输与算子计算重叠,但跨阶段无法把反向计算“藏进”下一轮前向计算;整体关键路径仍包含两段流程各自的灌满、排空开销,单步时延为 \((m+p-1)(t_f) + (m+p-1)(t_b)\)(\(t_f\) 为单个 micro-batch 在单个 stage 的前向时间,\(t_b\) 为反向时间)。
显存与 \(m\) 互相制约:为等待反向传输,每个 stage 必须长期保留本段的 \(m\) 份前向激活,造成显存压力;同时激活峰值近似为 \(M^{(i)}_{\text{act,peak}}\!\approx m\,L_i A_{\text{layer}}\)(\(L_i\) 为第 \(i\) 段包含的模型层数,\(A_{\text{layer}}\) 为单一层的激活张量大小),这直接限制了 \(m\) 的上限。
整体峰值显存公式可表示为:
微批切分的边际收益递减:增大 \(m\) 会引入更密集的启动/同步开销,同时减小单个计算核(per-kernel)的批量,可能抵消部分吞吐收益。综合来看,“两段式”PP 的瓶颈在于:要提升效率需增大 \(m\),但大 \(m\) 又受激活显存与系统长尾开销约束——这正是后续更先进调度方案试图突破的根本原因。
1.2 核心思想#
1F1B 的核心是让每个 micro-batch 的反向计算尽早折返,并与后续 micro-batch 的前向计算交错。与两段式“先全前向、再全反向”的调度过程不同,1F1B 在 warmup 完成后直接进入稳态:末段 stage 一旦完成某个 micro-batch 的前向计算,就立即启动该 micro-batch 的反向计算(因此得名 1F1B);与此同时,前端 stage 继续为后续 micro-batch 执行前向计算,如下所示。
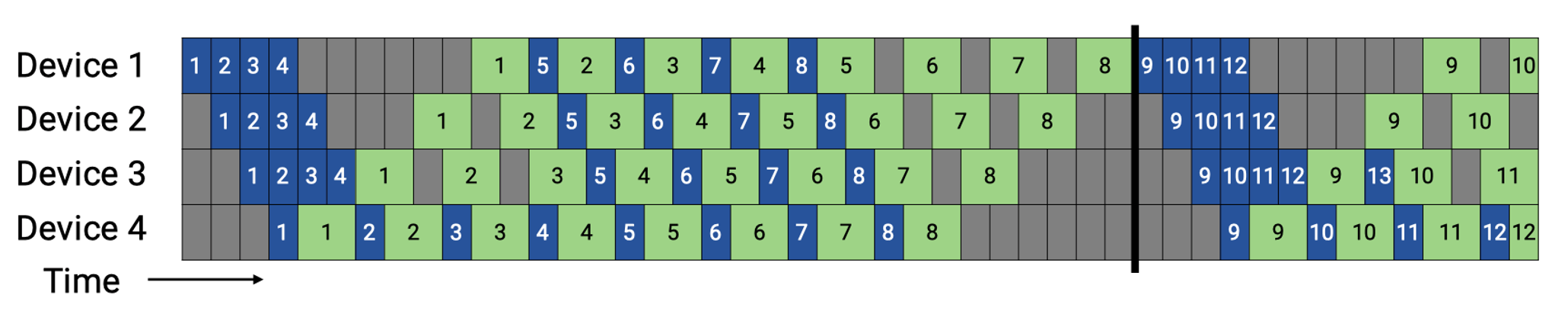
在这一机制下,反向梯度沿流水线向前回传,各 stage 在时间线上呈现“F(前向)→ B(反向)→ F → B…”的交替节奏,仅在流程开头/结尾保留不可避免的 warmup/cooldown 气泡。由于反向计算被尽早触发,同一份激活“从产生到被消耗”的时间距离,由 GPipe 的 \(O(m)\)(需等所有 micro-batch 前向完成)降至 \(O(p)\)(只需等反向计算折返到当前 stage),显著缩短激活驻留时间。
末段 stage 对第 \(j\) 个 micro-batch 完成前向计算后,立即启动该 micro-batch 的反向计算,无需等待其他 micro-batch;反向计算仅需沿流水线深度 \(p\) 折返到第 \(i\) 段。等待时隙近似为:
无“等完全部 \(m\) 个 micro-batch”的项,等待时长仅与流水线深度 \(p\) 相关,与 \(m\) 无关。
若不启用重计算,GPipe 的第 \(i\) 段 stage 在前向结束时需同时保留 \(m\) 份可反向激活,峰值近似 \(m\,L_i A_{\text{layer}}\);而 1F1B 在稳态交错下,每段 stage 同时“挂起”的在途 micro-batch 数量受 \(p\) 限制(记常数 \(k_i\!\sim\!O(p)\)),激活峰值近似为:
若启用重计算,激活峰值近似为:
其中 \(A_{\text{boundary}}\) 为 stage 边界的激活张量大小,\(\alpha\) 为重计算引入的激活系数(\(\alpha<1\))。
对比可见,1F1B 将激活峰值从 \(\mathcal{O}(m)\) 压至 \(\mathcal{O}(p)\),这是其“先天降低显存压力”的核心原因:即使在相同 \(m\) 下,1F1B 更省显存;或在相同显存预算下,1F1B 允许将 \(m\) 调得更大,从而进一步摊薄气泡、提升吞吐。
但需注意:1F1B 不直接减少气泡大小本身。定义气泡时间 \(t_{\text{bubble}}=(p-1)(t_f+t_b)\)、理想计算时间 \(t_{\text{ideal}}=m(t_f+t_b)\),则气泡率(bubble ratio)保持不变:
其中 \(p\) 为流水线深度(stage 数量),\(m\) 为 micro-batch 数量,\(t_f/t_b\) 为单个 micro-batch 在单个 stage 的前/反向时间。关键在于:\(t_{\text{bubble}}\) 的来源与调度方式无关——无论是两段式(GPipe)还是交错式(1F1B),都必须经历 \((p−1)\) 个“warmup/cooldown”的结构性头尾时延,这是由有限流水线深度决定的不可消除开销。
因此,1F1B 的核心改善是显存占用,而非气泡大小;但它通过降低显存压力,允许在相同显存预算下增大 \(m\),进而通过更大的 \(m\) 压低气泡率(\(\frac{p-1}{m+p-1}\) 随 \(m\) 增大而减小)——这是 1F1B 间接降低气泡占比、提升稳态吞吐的根本机制。
2. Virtual Pipeline 算法#
后续 Megatron-LM 在 1F1B 基础上,提出Interleaved 1F1B(交错式 1F1B),即虚拟流水并行(Virtual Pipeline Parallelism,VPP),用于进一步削减流水线气泡。其核心并非“通过增大 \(m\) 细化流水划分”,而是在每张物理 GPU 上引入 \(v\) 个“虚拟流水阶段(virtual pipeline stages),并通过交错调度(interleaving)填充空闲时间。
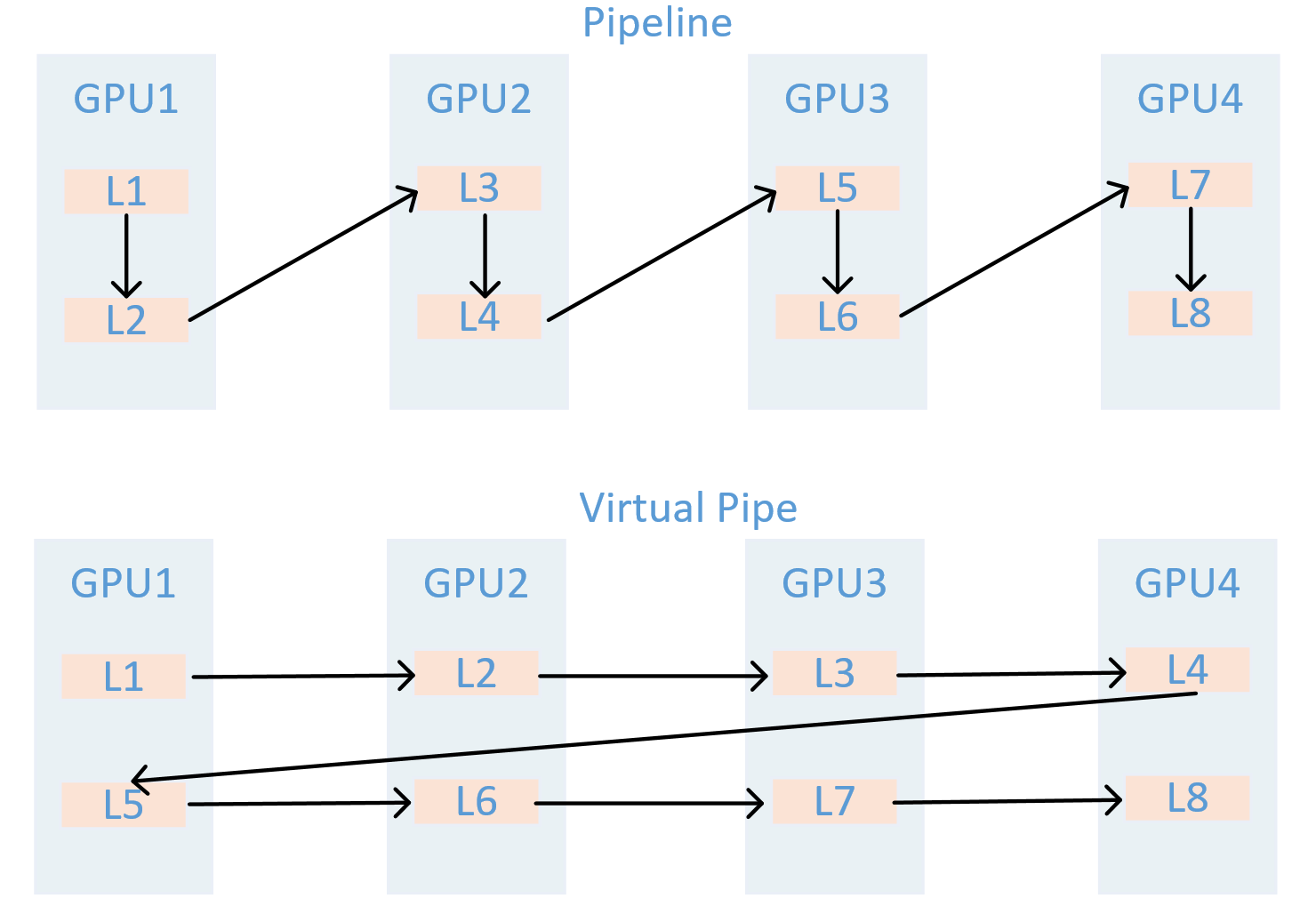
具体机制如下图所示:不同于 1F1B“单张 GPU 仅承担 1 个或多个连续 stage 计算”的方案——该方案会导致未执行计算的 GPU 因等待数据而空闲,VPP 采用虚拟化设计:将多个不相邻的流水线阶段计算任务,分配给同一张 GPU 承担;同时通过多个并行线程或 CUDA 流,在同一张 GPU 上交错执行不同虚拟阶段的前向/反向计算。这样,GPU 在等待上/下游数据的空隙中,可切换到本卡的其他虚拟阶段继续计算,充分利用原本的空闲(idle)时间。

2.1 虚拟化理解#
给定模型总层数 \(L_{\text{total}}\)、流水线并行度 \(p\)(物理 GPU 设备数)、虚拟并行度 \(v\)(每张 GPU 的虚拟阶段数),VPP 将模型划分为 \(p\times v\) 个连续、等长的层段,每个层段的长度为:
对第 \(d\in\{0,\dots,p-1\}\) 张 GPU,分配的虚拟阶段索引集合为:
即虚拟化的对象是“流水阶段”,因此同一张 GPU 负责 \(v\) 个不相邻的虚拟阶段(跨步映射)。执行时,为 \(\mathcal{S}_d\) 中的每个虚拟阶段各开启一条 CUDA 流,在 1F1B 语义下交错推进这些更小的前/反向计算片段:当某虚拟阶段因 P2P 传输(跨 GPU 数据传输)或上游依赖而空等时,GPU 立即切换到本卡的另一虚拟阶段执行计算,以此填充原本的空闲时隙。
2.2 降低气泡率#
在 1F1B 中,warmup/cooldown 过程需要跨越 \((p-1)\) 个固定的流水线阶段(因 \(p\) 恒定,即模型纵向切分的 stage 总数固定)。VPP 不减少流水线阶段总数,而是将“每次跨越单张 GPU 对应的流水线阶段时长”按 \(1/v\) 缩短——例如,非 VPP 场景下跨越单张 GPU 需执行 4 个流水线阶段的计算,VPP 仅需执行 1 个虚拟阶段的计算(因单张 GPU 承担 \(v=4\) 个虚拟阶段),即可进入下一张 GPU 执行下一阶段计算,如下所示:
若设非 VPP 场景下,单个 stage 的前/反向时间分别为 \(t_f、t_b\),则开启 VPP 后,单个虚拟阶段的前/反向时间缩短为:
由此,同样需要跨越 \((p-1)\) 次的气泡时间被压缩为:
理想计算工作量不变(\(t_{\text{ideal}}=m(t_f+t_b)\)),因此 VPP 的气泡率为:
直观解释:VPP 中,流水线仍需经历 \((p-1)\) 次跨 GPU 阶段切换,但每次切换仅需推进 \(1/v\) 的前/反向计算片段,因此总等待时隙宽度按 \(1/v\) 缩减;理想计算量不变,故气泡率与虚拟并行度 \(v\) 成反比。
VPP 的“虚拟化”并非合并多张 GPU,而是在每张 GPU 内拆分出 \(v\) 个虚拟流水阶段,通过并行/交错推进更小的前/反向片段填补空闲时隙。其最终效果是:在不改变总算量与 1F1B 低激活驻留优势的前提下,将气泡时间缩小为 1F1B 的 \(\tfrac{1}{v}\) 倍(\(\text{bubble ratio}^{\text{VPP}}=\tfrac{1}{v}\cdot\tfrac{p-1}{m}\)),但代价是通信频率与通信量均提升 \(v\) 倍。
2.3 VPP 通信开销#
VPP 的通信开销体现在通信频率提升与通信容量提升两个方面:
相比于非 VPP 流水线技术(如 1F1B),由于每张 GPU 承载 \(v\) 个虚拟阶段,单个 micro-batch 需以 1F1B 的方式穿过 \(p\times v\) 个虚拟流水线阶段,而非仅穿过 \(p\) 个物理阶段。这导致跨 GPU 跃迁次数大幅增加,如下图所示:

场景 |
条件 |
前向跨 GPU 跃迁次数 |
反向跨 GPU 跃迁次数 |
|---|---|---|---|
非 VPP |
(v=1) |
(p-1) |
(p-1) |
VPP |
(v>1) |
(pv-1 ;\approx; v(p-1)) |
(pv-1 ;\approx; v(p-1)) |
理解了通信次数的额外开销,通信量的额外开销就好理解了,若设单次跨 GPU 通信的激活量为 \(S\) 字节(梯度大小与激活量同阶),则两类场景的通信量对比为:
场景 |
条件 |
前向全路径通信字节 |
反向全路径通信字节 |
单个 micro-batch 合计通信字节 |
|---|---|---|---|---|
非 VPP |
(v=1) |
((p-1)S) |
((p-1)S) |
((p-1)\times 2S) |
VPP |
(v>1) |
((pv-1)S \approx v(p-1)S) |
((pv-1)S \approx v(p-1)S) |
(v(p-1)\times 2S) |
与非 VPP(\(v{=}1\))相比,VPP 的通信频率提升 \(v\) 倍,总通信字节量也提升 \(v\) 倍——即 VPP 以“通信开销×\(v\)”为代价,换取“气泡率÷\(v\)”的收益。
3. PipeDream-2BW 算法#
3.1 核心思想#
在不执行周期性 flush(流程中断)的前提下,兼顾高吞吐与低显存,同时尽量贴近数据并行的权重更新语义。将 1F1B 调度与双缓冲权重(2-Buffered Weights,简称 2BW)、梯度合并(coalescing) 结合:
每个 stage 仅保留两份权重版本——
current(当前正在使用的权重版本)与shadow(待更新的权重版本),而非原始 PipeDream 可能需要的最多 \(p\) 份(\(p\) 为流水线深度);对同一 micro-batch 的前向/反向计算,严格使用同一份权重(消除“权重版本不一致”问题);
权重更新采用“1-stale 语义”(即更新时使用上一批次的梯度),避免 flush 引起的流程停顿。
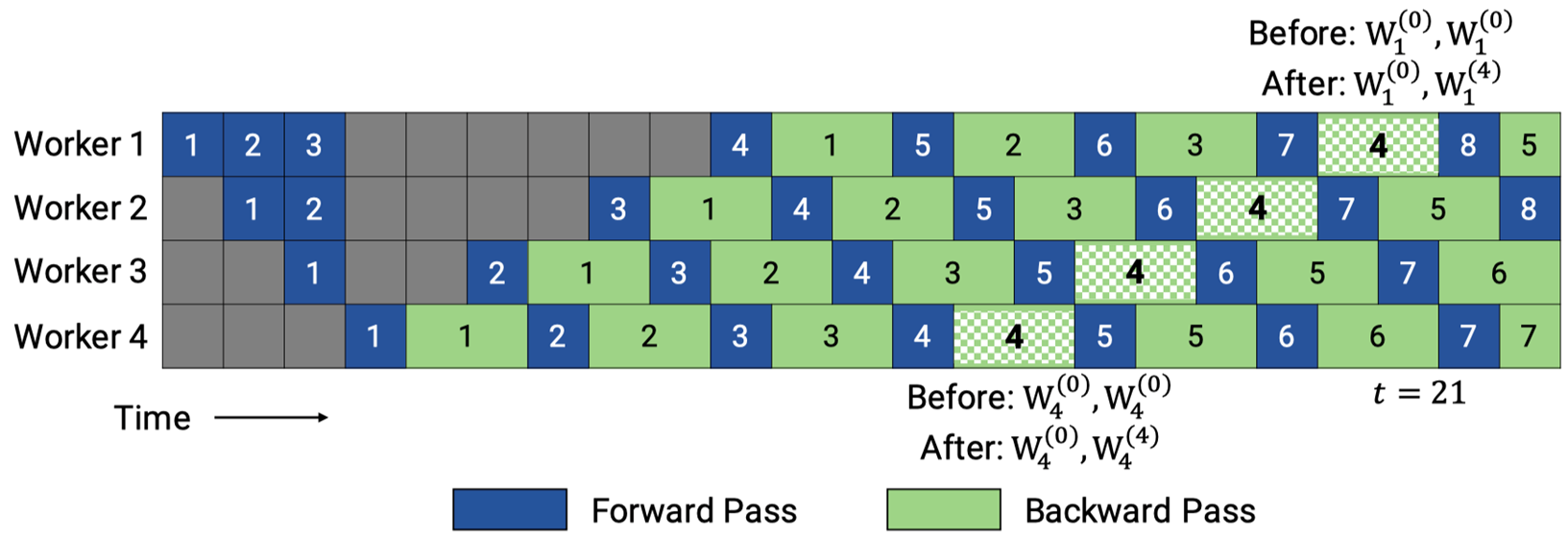
3.2 调度机制#
!!!!!!!!!下面这段缺乏上下文逻辑了,简单修改下
基础调度逻辑:仍遵循 1F1B 规则,各 stage 交替执行不同 micro-batch 的前向/反向计算;
权重版本滚动:每处理完 \(m\) 个 micro-batch(梯度在 \(m\) 个 micro-batch 内合并),生成 1 个新权重版本(
shadow升级为current,旧current丢弃);且要求 \(m\ge p\)(确保流水线内的在途 micro-batch 均能使用对应版本权重),常见简化设定为 \(m=p\);版本兼容性:新权重版本仅供“新进入流水线的 micro-batch”使用,流水线中已在执行的在途 micro-batch,继续使用其前向计算时的旧版本权重完成反向——因此每个 stage 最多只需保留 2 份权重(
current+shadow),无额外版本冗余。
直观理解:权重版本的推进以“\(m\) 个 micro-batch 为 1 批”滚动;一旦旧版本权重对应的所有在途 micro-batch 完成反向计算,该旧版本即可立即丢弃,因此内存占用上限被固定为“2 份权重”,避免原始 PipeDream 中“多版本权重占用大量显存”的问题。
3.3 更新 1-stale 与优化器#
设批级权重为 \(W(t)\)(\(t\) 为批索引),批平均梯度为 \(\nabla f(W)\)(基于权重 \(W\) 计算的梯度):
标准小批 SGD:权重更新依赖当前批梯度,即 \(W(t{+}1)=W(t)-\nu\,\nabla f(W(t))\)(\(\nu\) 为学习率);
PipeDream-2BW(1-stale 语义):权重更新依赖上一批梯度,即 \(W(t{+}1)=W(t)-\nu\,\nabla f\big(W(t{-}1)\big)\)。
其中“1-stale”表示“梯度延迟 1 个批次”,且该延迟对所有 stage 一致。实验表明,1-stale 语义与标准小批 SGD 的收敛效果相当;对于动量(Momentum)、Adam 等优化器,也可直接平移至“1-stale 梯度”场景,无需额外引入影子变量。
3.4 显存与吞吐优势#
显存优化:
权重版本:仅 2 份(2BW),远少于原始 PipeDream 的最多 \(p\) 份,权重显存占用大幅下降;
激活显存:仅需缓存“在途 micro-batch”的激活,量级随 1F1B 保持 \(\mathcal{O}(p)\),远低于两段式(GPipe)在大 \(m\) 下的 \(\mathcal{O}(m)\)。
吞吐优势: 无 flush 导致的结构性空转,稳态效率显著高于 GPipe;据相关论文报告,对 GPT/BERT 类模型,PipeDream-2BW 可比传统优化基线加速 1.3×–20×,较 GPipe 加速可达 3.2×。
PipeDream-2BW = 1F1B 调度 + 双缓冲权重 + 批内梯度合并 + 1-stale 更新。其核心价值是将原始 PipeDream 的“多版本权重、不均匀梯度延迟”,收敛为“每 stage 最多 2 份权重、全 stage 统一 1-stale 延迟”,最终在不中断流程(无 flush)的前提下,实现“高吞吐、低显存、收敛效果贴近数据并行”的目标。
4. Zero-Bubble 算法#
!!!!!!!!图应该放在文字介绍下面,至少文字介绍是对着图来的,而不是只有个简单的图。

4.1 核心思想#
ZB(Zero-Bubble)系列的关键创新是将反向传播拆分为两个独立子过程:
\(B_\text{in}\)(Input Gradient Calculation,输入梯度计算):计算“需向上游 stage 传输的输入梯度”,即把梯度往上游传递;
\(B_\text{w}\)(Weight Gradient Calculation,权重梯度计算):计算“当前 stage 局部权重的梯度(dW)”,仅用于本地权重更新。
关键依赖变为:\(B_{\text{in}}^{(s,j)}\) 只依赖 \(B_{\text{in}}^{(s+1,j)}\),\(\quad B_{\text{w}}^{(s,j)}\) 依赖 \(\big(F^{(s,j)},B_{\text{in}}^{(s,j)}\big)\),这使得 \(B_{\text{w}}\) 可以在许多本来空闲的时隙中穿插执行,以填满气泡。因此通过拆分反向过程,ZB 可将 \(B_\text{in}\)、\(B_\text{w}\) 作为“可自由插入的子片段”,填充流水线中原本不可避免的空闲时隙,从而在同步训练语义下将气泡压至接近 0。其中 ZB-V(V-Shaped ZB)是一类手工设计的调度方案:每张 GPU 负责 2 个模型分块(chunk,即拆分后的子模型段),前向计算与两段反向子过程(\(B_\text{in}\)、\(B_\text{w}\))的依赖关系在时间轴上呈“V”字形,因此得名 ZB-V。
4.2 V 字形调度机制#
!!!!!!!!!!用自己的理解和语言描述,不要大模型的总结式列表。
模型分块与执行逻辑:将每个物理 stage 进一步拆分为 2 个 chunk,安排它们在时间线上以“F → \(B_\text{in}\) / \(B_\text{w}\)”的交错方式执行;相邻物理 GPU 上的 2 个 chunk 彼此错位,使“一个 chunk 的 \(B_\text{w}\) 计算”能精准填充“另一个 chunk 的空闲时隙”。
稳态特征:前向计算(\(F\))与两段反向子过程(\(B_\text{in}\)、\(B_\text{w}\))交替推进,将 1F1B 中“尾部 cooldown 暴露的空隙”用 \(B_\text{w}\) 完全塞满。因此“零气泡”的实现条件是:单 chunk 的 F 时长 ≈\(B_\text{in}\) 时长 ≈ \(B_\text{w}\) 时长;若三者时长不匹配,仍会留下少量残余空隙(需通过贪心调度或自动调度策略补偿)。
直观理解:相比 1F1B 仅用“F、B”两种计算片段拼合时间轴,ZB-V 新增了“\(B_\text{in}\)、\(B_\text{w}\)”两种子片段,可在更细粒度上“填补时间缝隙”。当 \(F\)、\(B_\text{in}\)、\(B_\text{w}\) 的时长接近时,子片段能恰好填满所有空闲时隙,实现“气泡≈0”;若某一子片段时长过短/过长,仍会出现微小空隙,但远小于 1F1B 的气泡。
4.3 何时能实现 ZB?#
!!!!!!!!!!用自己的理解和语言描述,不要大模型的总结式列表。
理想条件:若单 chunk 的 \(F\) 时长 = \(B_\text{in}\) 时长 = \(B_\text{w}\) 时长,ZB-V 可在同步训练语义下实现严格“零气泡”。实际模型中,三者时长难以完全相等,需引入贪心调度(如动态调整子片段执行顺序)或搜索式调度(如基于模型结构预计算最优时序),尽可能靠近零气泡。
工程优化要点:ZB-V 论文还提出“绕过优化器步的同步屏障”——传统同步训练中,所有 stage 需等待全局优化器更新完成才能推进,这会引入尾部屏障气泡;ZB-V 通过“局部权重更新与全局同步解耦”,进一步消除该屏障,是达成“真正零气泡”的关键工程手段。
通信/内存代价#
!!!!!!!!!!用自己的理解和语言描述,不要大模型的总结式列表。
激活峰值控制:ZB-V 的设计可在“不抬升 1F1B 激活峰值”的前提下显著减泡;若将“零气泡”作为硬性约束,通常需提升激活显存预算(文献报告“接近零气泡”的现实设定下,激活显存约为 1F1B 的 2×);而在“F≈B_in≈B_w”的理想均衡下,激活显存最低可降至“参数-激活校准内存的 1/2”(即参数与激活的显存占比更均衡)。
权重与版本:ZB-V 无需像原始 PipeDream 那样存储多份权重版本,其核心优化在于“\(B_\text{in}\)/\(B_\text{w}\) 的算子级时序切分”,在 1F1B 的低激活驻留量级(≈O(p))基础上,做更精细的时间编排——因此权重显存仍保持低占用。
通信条数增加:与 VPP 类似,更细粒度的子片段(F、\(B_\text{in}\)、\(B_\text{w}\))意味着更多 stage 边界的通信消息;同时 \(B_\text{in}\)、\(B_\text{w}\) 的交错执行会引入额外的依赖关系与消息序列,需通过“多 CUDA 流 + NCCL 多通道 + 分块通信”等技术隐藏通信延迟(即让通信与计算重叠)。
调度复杂度提升:需开发专用调度器,管理“\(F\)/\(B_\text{in}\)/\(B_\text{w}\)”三类片段的事件依赖(如“\(B_\text{in}\) 需在 \(F\) 之后执行”“\(B_\text{w}\) 可与其他 chunk 的 \(F\) 并行”)与“何时插入子片段”的策略;目前 ZB-V 的官方实现已在 Megatron-LM 分支开源,包含通用运行时与不同 ZB 族调度方案。
ZB-V 通过“拆分反向为 \(B_\text{in}\)/\(B_\text{w}\)”与“V 字形双 chunk/卡调度”,让前向/反向子片段更细粒度地占满时间轴;在 \(F\approx B_{\text{in}}\approx B_{\text{w}}\) 的理想条件下可实现近乎零气泡,同时维持接近 1F1B 的激活驻留量级,但需承担“更复杂的调度逻辑”与“更多的通信消息”。落地时需依赖成熟的开源实现(如 Megatron-LM 的 ZB 分支)与“通信-计算重叠”优化。据文献数据,在类似内存预算下,ZB-V 相对 1F1B 的吞吐提升可达 15–23%;若放宽内存预算(允许 2×激活占用),吞吐提升可至 30%,体现其“以细粒度时序填补空隙”的核心优势。
5. 近年 PP 算法总结#
5.1 PP 算法优化点与演进#
!!!!!!!!!!用自己的理解和语言描述,不要大模型的总结式列表。
基线:1F1B(非 VPP) 交替执行前/反向,消除了“等待全部 (m) 个 micro-batch”带来的长尾等待;激活驻留量级为 \((\mathcal{O}(p))\)。
Interleaved 1F1B / VPP 在每卡引入 (v>1) 个“虚拟 stage”,用交错调度在同一 GPU 内切换执行多个不相邻的虚拟段,以更细粒度片段填充空隙:
\[ \begin{align}\begin{aligned}\text{bubble ratio}^{\text{VPP}}=\frac{1}{v}\cdot\frac{p-1}{m} $$. 代价是通信频率与通信量均 $(\times v)$:单个 micro-batch 的全路径通信字节由 $(2S(p-1))$ 增至 $(2S\cdot v(p-1))$;跨 GPU 跃迁次数由 $(p-1)$ 增至 $(pv-1\approx v(p-1))$。\\* **PipeDream-2BW** 在 1F1B 框架上,用双缓冲权重(2-Buffered Weights, 2BW)与批内梯度合并保证“前/反向使用同一份权重”,形成统一的 1-stale 更新语义: $$W(t{+}1)=W(t)-\nu\,\nabla f\big(W(t{-}1)\big)\end{aligned}\end{align} \]每个 stage 仅需 2 份权重(
current/shadow),显著降低权重显存;常见设定 \((m\ge p)\)(多取 \(m=p\))。Zero-Bubble(以 ZB-V 为例) 将反向拆为 \(B_\text{in}\)(向上游的输入梯度)与 \(B_\text{w}\)(本地权重梯度),在时间轴上与前向 F 交错成“V”字形,以更细颗粒子片段填满空隙;当 \((F\approx B_{\text{in}}\approx B_{\text{w}})\) 时,气泡可逼近 0。工程上需多流/多通道与分块通信掩蔽更高的消息数与依赖开销。
5.2 衍生 PP 算法对比#
算法/范式 |
关键机制与粒度 |
气泡/等待(稳态) |
显存占用(激活/权重) |
通信代价(频次×字节) |
更新语义 / 一致性 |
适用要点与限制 |
实现复杂度 |
|---|---|---|---|---|---|---|---|
1F1B(非 VPP) |
stage 级交替 F/B |
等待量级 ~ 𝒪(p);无“等完 m”长尾 |
激活 ~ 𝒪(p);权重可 1 份 |
跨卡跃迁:前/后各 p−1;单 mb 字节 ≈ 2S(p−1) |
标准(可 0-stale) |
m≥p 性能更稳;算子不均衡/通信抖动需对齐 |
低 |
Interleaved 1F1B / VPP |
每卡 v 个虚拟 stage,交错推进 |
气泡率 ≈ (1/v)·((p−1)/m) |
激活 ~ 𝒪(p);权重同 1F1B |
频率×v,字节×v:跃迁 ≈ pv−1;总字节 ≈ 2S·v(p−1) |
与 1F1B 一致 |
受带宽/NVLink 拓扑限制;v 过大得不偿失 |
中 |
PipeDream-2BW |
1F1B + 双缓冲权重 + 批内合并 |
无 flush;高吞吐,尾部空转小 |
激活 ~ 𝒪(p);权重恒 2 份(2BW) |
近似 1F1B;合并通信以提升重叠度 |
1-stale(统一) |
常设 m≥p(多取 m=p);适合长序列/大模型 |
中 |
Zero-Bubble(ZB-V) |
反向拆分 \(B_\text{in}\)/\(B_\text{w}\),V 字形双 chunk |
目标 bubble → 0(需 F≈B_in≈B_w) |
激活 ~ 𝒪(p);若追求严格零泡,峰值↑ |
消息条数更多;需多流/多通道/分块重叠隐藏通信 |
同步语义(无权重多版本) |
需算子/chunk 时长配平;依赖管理复杂 |
高 |
总结与思考#
1F1B 调度(PipeDream)通过“前向与反向计算尽早交错”,显著降低激活峰值显存(从 \(\mathcal{O}(m)\) 至 \(\mathcal{O}(p)\)),从而在相同硬件条件下支持更大规模模型或更深流水线。在此基础上,各衍生技术从不同维度优化:
Virtual Pipeline(VPP):通过“在每张物理 GPU 拆分 \(v\) 个虚拟阶段”,将气泡率降低至 1F1B 的 \(\tfrac{1}{v}\),但代价是通信量与通信频率均提升 \(v\) 倍,适合“通信带宽充足、追求低气泡”的场景;
PipeDream-2BW:结合“双缓冲权重”与“1-stale 更新语义”,将权重版本数量固定为 2 份,在保持 1F1B 高吞吐的同时进一步压缩权重显存,适合“显存紧张、需贴近数据并行收敛语义”的场景;
ZB-V(Zero-Bubble PP):通过“拆分反向为 B_in/B_w”与“V 字形调度”,在 \(\mathcal{O}(p)\) 激活量级下将气泡压至接近 0,代价是调度复杂度与通信条数增加,适合“对吞吐要求极高、可承担工程复杂度”的场景;
这些技术的核心逻辑均围绕“平衡显存、气泡、通信三者关系”——无绝对最优方案,需根据硬件条件(显存/带宽)、模型规模、训练目标(吞吐/收敛速度)灵活选择,或组合使用(如 VPP 与 ZB-V 叠加)以最大化并行效率。