Stable Diffusion#
Author By: 杨智超
一、引言:AI 图像生成的革命性突破#
1.1 为什么 Stable Diffusion 引发行业热潮?#
2022 年,Stable Diffusion 的横空出世标志着 AI 行业正式迈入 AIGC(AI Generated Content)时代,成为推动行业变革的核心引擎。作为 AI 绘画领域的里程碑式模型,Stable Diffusion 不仅实现了文生图(txt2img)和图生图(img2img)等核心功能,更以全面开源的策略彻底改变了 AI 技术的传播与应用模式。
Stable Diffusion(简称 SD)是 AI 绘画领域的一个核心模型,能够进行文生图(txt2img)和图生图(img2img)等图像生成任务。并且,Stable Diffusion 完全开源(模型、代码、数据、论文、生态等),这使得其能快速构建强大繁荣的上下游生态(AI 绘画社区、基于 SD 的自训练 AI 绘画模型、丰富的辅助 AI 绘画工具与插件等),并且吸引了越来越多的 AI 绘画爱好者加入其中,与 AI 行业从业者一起推动 AIGC 领域的发展与普惠。
Stable Diffusion 的真正革命性在于它实现了 AI 技术的 ToC 普惠——让普通用户也能轻松参与内容创作,使 AI 绘画真正融入全球日常生活。这与传统深度学习时代"技术精英化"的模式形成鲜明对比,标志着 AIGC 从工业级应用迈向大众化创作的转折点。
正是这种开放、共享、共创的模式,为未来十五年 AI 技术的爆发性发展奠定了基础。当开源生态与大众创作热情相互激发,我们正见证着一个与移动互联网时代同等重要的技术变革浪潮正在形成。Stable Diffusion 不仅是一个模型,更是开启 AI 普惠新时代的钥匙,预示着 AI 将如互联网一样,成为每个人日常生活与工作中的基础工具。
1.2 从 DALL·E 到 Stable Diffusion:图像生成技术演进简史#
图像生成技术的发展史,在近几年大模型和算力的飞速发展下,日新月异。
2021 年,OpenAI 推出的 DALL·E 及其后续版本,首次实现了文本到图像的高质量生成,但其计算需求极高,仅限于大型科技公司和研究机构使用。这些模型需要强大的计算资源,生成一张高质量图像往往需要数分钟甚至更长时间,价格也相当昂贵。
2022 年下半年,Stable Diffusion 的开源成为行业分水岭。它基于 Latent Diffusion 架构,将图像压缩到潜在空间进行扩散过程,大幅降低了计算需求。这一技术突破使得 Stable Diffusion 能在消费级 GPU 上运行,单次生成时间从分钟级缩短至秒级,成本近乎为零。
Stable Diffusion 的开源策略更是点燃了行业热情。GitHub 上短短几个月内涌现出大量基于该模型的二次开发项目,形成了完整的生态系统。这与 DALL·E 等闭源模型形成了鲜明对比,后者需要通过 API 调用,限制了开发者的自由度和创新空间。
二、Stable Diffusion 基础认知#
2.1 什么是 Stable Diffusion?—— 一句话定义#
Stable Diffusion是一种基于扩散原理的开源AI图像生成模型。
2.2 核心优势:开源、高效、低门槛#
Stable Diffusion 的核心优势可归纳为“开源、高效、低门槛”,这些特性共同驱动了它在 AIGC 领域的迅速普及。首先,开源不仅意味着模型权重、代码和训练细节公开,还带来了极高的透明性和可复现性:研究者与工程师可以自由复现、审计与改进模型,社区快速迭代出大量插件、工具与微调策略,形成丰富生态。其次,高效体现在架构设计与工程优化上:Stable Diffusion 在潜在空间(latent space)中做扩散,显著降低了计算量;配合半精度(FP16)、裁剪/量化、TensorRT 等优化后,能够在消费级 GPU 上实现秒级推理,便于在线部署与规模化服务。最后,低门槛既指运行门槛,也指参与门槛——普通开发者和爱好者只需一块中端显卡即可试验与微调模型,丰富的教程与预训练资源让入门更容易;此外,开源生态使得商业化落地变得灵活(易定制、可本地部署、可控制隐私与数据流向)。综上,Stable Diffusion 通过技术与生态双轮驱动,实现了从研究到产品再到大众创作的快速通道,但在落地时仍需注意模型许可、训练数据合规及生成内容的安全与审核策略。
2.3 与传统 AI 图像工具的关键区别#
开源生态、运行门槛、可玩性是Stable Diffusion与传统AI图像工具主要的关键区别。
Stable Diffusion 是完全开源的,模型、代码、数据和生态工具都是对外开放的,你完全可以基于开源的项目打造自己的AI图像生成模型。而传统AI图像工具,多是厂家收费闭源工具,创新完全受限于厂商。这实现了AI技术的ToC普惠,让普通用户也能参与模型测的AI创新。
运行门槛极低,Stabel Diffusion 基与扩散模型来构建,普通消费级GPU即可微调训练和推理,即使是从零开始训练一个SD2的模型,费用也可低于5万美金,在A100GPU中运行23825个小时即可完。在推理侧,结合最新的TensorRT量化方案即便是在入门级消费显卡4060,也可实现高效部署。总的来说,不管是训练还是推理Stabel Diffusion都已经有相当成熟的方案。
Stable Diffusion的可玩性也是其另外一大卖点,不管是文本生成图像(txt2img)、图生图(img2img)、文本加图生图等多种模式,都一并支持。相比传统工具的功能单一、可控性弱,Stable Diffusion无疑是非常成功的框架。
三、核心技术原理深度解析#
3.1 扩散模型基础 DDPM:噪声添加与逆转过程#
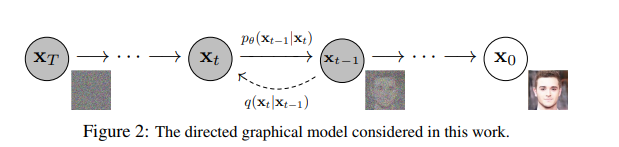
想象一下,你有一张清晰的图片,但想通过某种方式"忘记"它的细节,让它变成一团模糊的噪声。然后,你再尝试从这团噪声中"重建"出原来的图片。扩散模型就是通过这样的"破坏-重建"过程来学习生成新图像的。
DDPM 全称是 Denoising Diffusion Probabilistic Models,最开始提出是用于去噪领域。原始论文中数学公式比较多,需要一定的数理基础。
扩散模型的精髓在于:它不是直接学习如何生成图像,而是学习如何从噪声中恢复图像。 这种思路与传统的 GAN 或 VAE 完全不同,它通过一个渐进的过程来实现。
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process)。
如图所示,从 \(X_0\) 到 \(X_t\) 的过程,其实就是不断地给真实图片加噪声,经过 \(T\) 步加噪之后,噪声强度不断变大,得到一张完全为噪声地图像。整个扩散过程可以近似看成一次加噪即变为噪声图,那么其实我们只需要搞清楚其中一步加噪就可以了。
\(f(x)\) 在公式中有明确的定义: $\(X_t=\sqrt{1-\beta_t}*X_{t-1}+\sqrt{\beta_t}*Z_t\quad Z_t\sim N(0,I)\)$
\(t\) 是时间序列中一个值,取值范围为是 \([0, T]\) 对应时间产生的随机噪声,\(β_t\) 是超参数,也是序列中的一个值,在论文的实验部分,其经验值范围是 \([10^{-4},0.02]\) 线性变化,而且一般来说,\(t\) 越大,\(β_t\) 的取值也就越大(一开始,加一点点噪声就能比较明显的看出和原图的区别,越到后面,图像退化的越厉害,轻微的扰动已经看不出明显的变化,所以 \(β_t\) 的值需要更大)
训练的时候,为了提升训练效率,可以直接从 \(X_0\) 扩散成 \(X_t\)。经过复杂的公式推理,即可得到
3.2 Stable Diffusion 的创新架构#
3.2.1 U-Net 主干网络的作用#
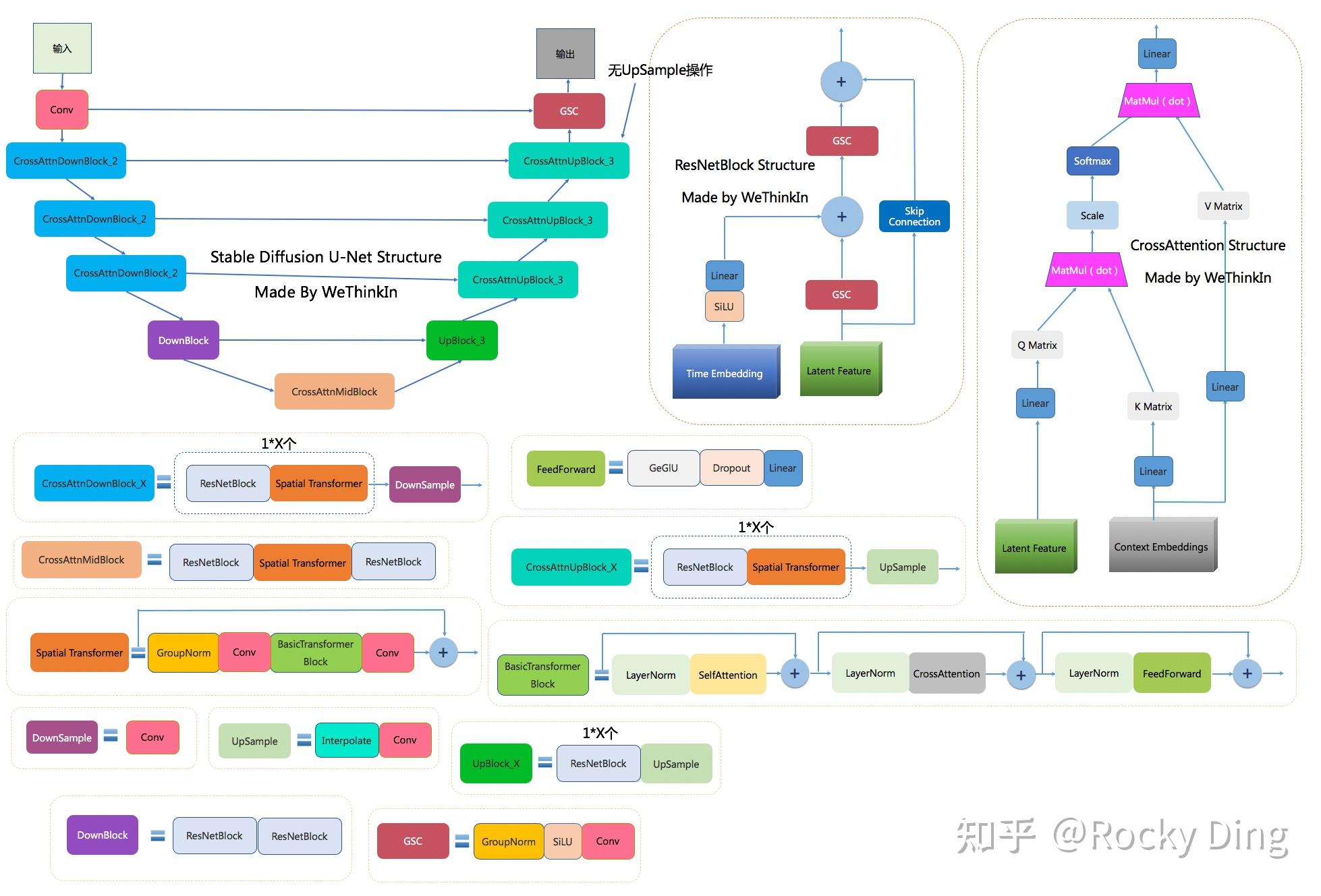 如简介图中所示,SD中的Unet结构是一个融合了传统分割AI模型与Cross Attention特征融合结构的图像Latent feature生成器。
如简介图中所示,SD中的Unet结构是一个融合了传统分割AI模型与Cross Attention特征融合结构的图像Latent feature生成器。
除此之外U-Net引入了时间信息step,来模拟随时间变化噪声扰动的过程,让SD模型能够更好的理解时间相关性。需要注意的是,U-net模块是多次调用的,这是为了从低维到高维有一个渐变的过程,如从整体上先描绘了一张图的轮廓,再逐步深入每一处的细节。
3.2.2 CLIP 文本编码器的智能融合#
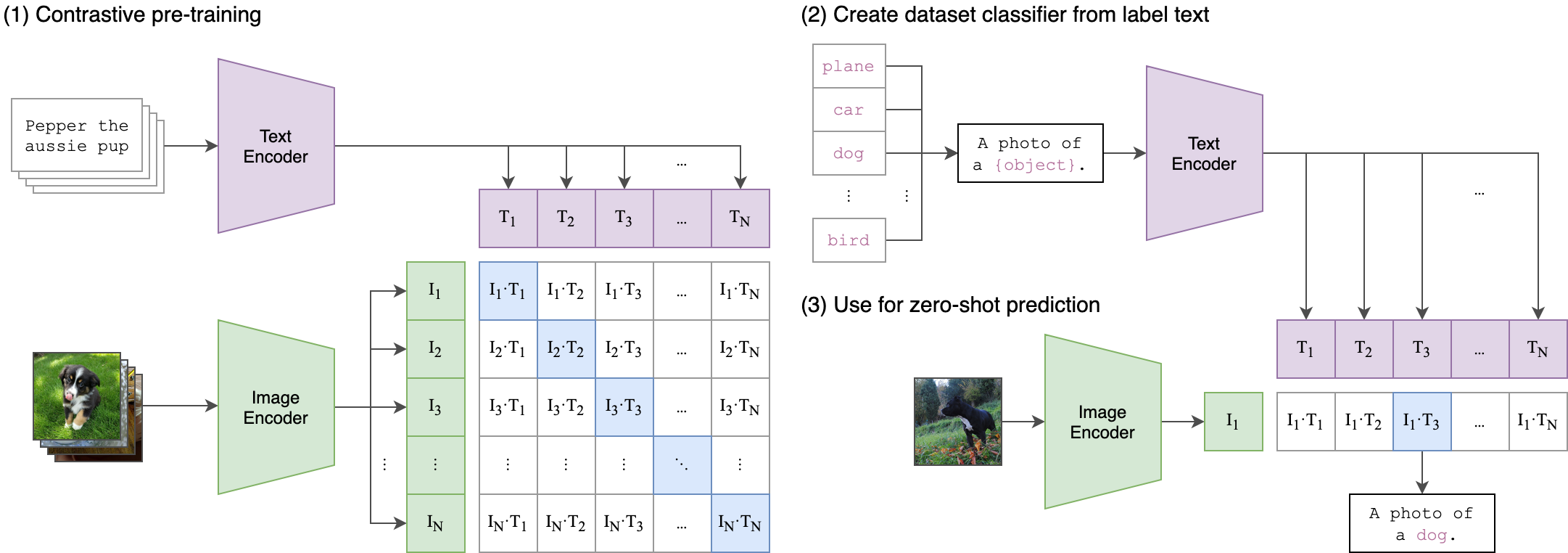
clip是非常经典的多模态特征提取器,在SD2中主要选择了使用其文本Text Encoder模型。其简洁高效的实现方式使得语言和文本的壁垒被打通,同时其强大的文本标签数据库使的clip模型拥有无与伦比的zero-shot能力。
3.2.3 VAE 编码器的图像压缩机制#

VAE模型主要起到图像的压缩和图像重建的作用,比如输入一个 H x W x C 的数据,同时比率为f, 你会得到一个 Hf、Wf高度、宽度的图像。当f小于1时,其为下采样,当f大于1时,其为上采样。
3.3 为什么它能实现高质量生成?#
SD模型充分借鉴了传统CV模型的处理技巧,如残差与U-Net结构,同时融合Transformer对图像、文本编码解码的最新趋势,可谓集合了众家之长。