06.Paged Attention 原理(DONE)#
Author by: 张艺蓉
1. 大模型推理内存挑战#
1.1 内存管理核心难题#
大模型推理中,处理请求的数量直接受 GPU 内存容量限制,推理服务吞吐量呈 memory-bound 特性。要突破这一限制,需解决三类关键内存管理挑战:
KV Cache 内存占比高。KV Cache 存储每个 Token 的 Key 和 Value 高维向量(按模型层独立存储),其大小随请求数量、序列长度呈线性增长,如图所示,KV Cache 所占内存可接近大模型参数的 50%。
解码策略多样性。大模型推理支持并行采样、束搜索等多种解码策略,不同策略对 KV Cache 的读写模式、生命周期管理要求差异显著。
序列长度不确定性。输入 prompt 长度各异,且生成式任务的最终输出长度无法提前预判,导致内存需求动态波动。

1.2 常规管理方式缺陷#
传统 NN 推理框架采用 连续内存静态预分配 机制:将同一请求的 KV Cache 按连续地址存储,预先分配 (batch_size, max_seq_len, hidden_dim) 固定尺寸的内存块。这种方式会造成三类严重内存浪费:
预留空间闲置。为未生成的 Token 预留的内存块长期处于空闲状态。
内部碎片。过度预留最大序列长度,导致实际序列长度与预分配空间不匹配,剩余部分无法被其他请求利用。
外部碎片。内存分配器频繁分配/释放不同大小的连续块,导致空闲内存分散为多个小片段,无法满足新请求的连续内存需求。

2. PagedAttention 设计思路#
为解决静态预分配的内存浪费问题,vLLM 项目创新性提出 PagedAttention 动态内存管理算法,核心思想直接借鉴操作系统经典的 虚拟内存与分页技术,实现 KV Cache 显存的高效利用。
具体映射关系为:将 KV Cache 的“块(Block)”类比操作系统的“物理页(Physical Page)”,“块表(Block Table)”类比“页表(Page Table)”,序列中 Token 位置对应的“逻辑块索引”类比“虚拟地址”。
通过这一设计,PagedAttention 首次将“逻辑上连续、物理上分散”的内存管理思想迁移至 GPU 显存,带来两大核心优势:彻底消除外部碎片(物理块无需连续)、支持细粒度内存共享(多序列可共享物理块),最终显著提升显存利用率与推理系统吞吐量。
2.1 虚拟内存核心概念#
PagedAttention 的设计根基是操作系统虚拟内存机制,其核心逻辑如下:
如图所示操作系统为每个程序提供 独立的、连续的虚拟地址空间,但程序数据实际存储在物理内存中 不连续的物理页面(通常为 4KB/8KB)中。
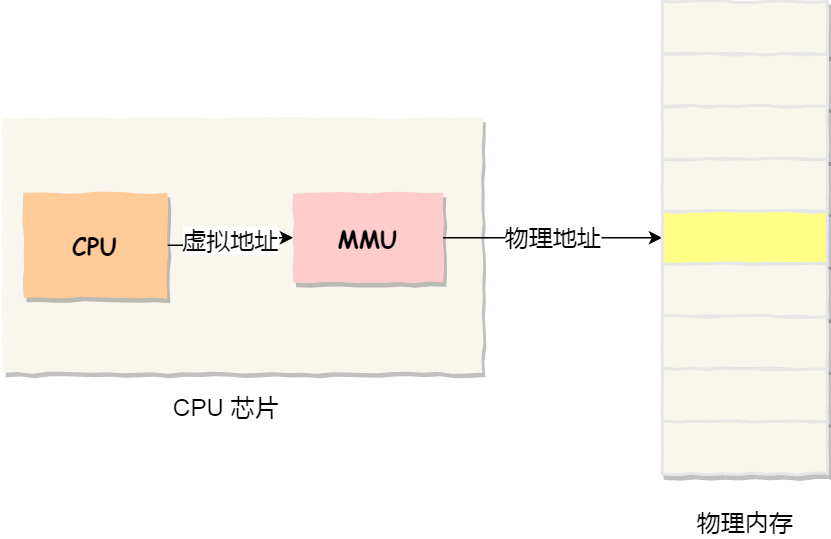
系统通过 页表(多级结构) 建立虚拟地址与物理页面的映射关系——页表记录每个虚拟页面对应的物理页面编号,如同“地址翻译词典”。这一机制的核心价值的是:
消除外部碎片。数据可分散存储在任意可用物理页面,无需寻找连续大内存块,只要总空闲物理内存充足即可运行。
灵活内存调度。支持数据在物理内存与硬盘间“换入(Page-in)”“换出(Page-out)”,突破物理内存容量限制;同时支持写时复制(Copy-on-Write, CoW)等高级特性,实现内存高效共享。
这种“逻辑连续、物理分散”的核心思想,为解决 GPU 显存这类稀缺资源的管理问题提供了关键启发。
2.2 算法核心机制#
PagedAttention 算法的核心是将 KV Cache 按固定大小拆分,通过块表管理映射关系,具体设计如下:
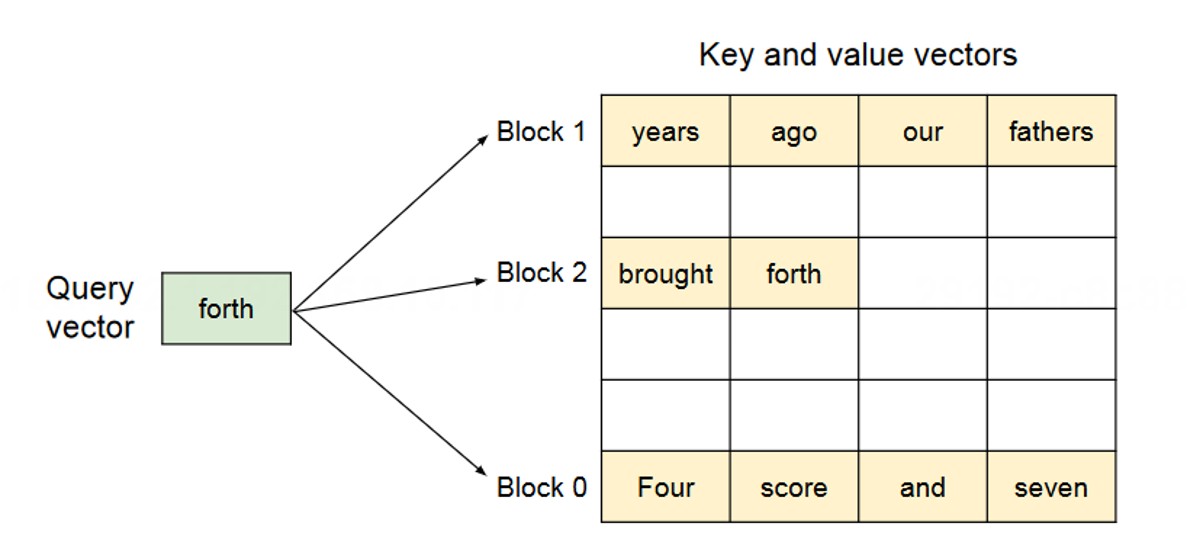
块划分机制:不再为每个序列预留连续大内存,而是将所有序列的 KV Cache 统一拆分为 固定大小的物理块。每个物理块可存储固定数量的 Token 对应的 Key 和 Value 向量(典型值为 16/32 个 Token,块大小需平衡内存利用率与调度开销),物理块在显存中可非连续存储。
块表映射管理:为每个序列维护一张独立的“块表(Block Table)”,记录该序列的“逻辑块”到显存“物理块”的映射关系。逻辑块按序列 Token 顺序连续编号,物理块则由内存管理器统一分配,无需与逻辑块顺序一致。
2.3 单请求处理流程#
以推理请求 prompt“Four score and seven years ago our”为例,详细拆解 PagedAttention 的完整工作流程:
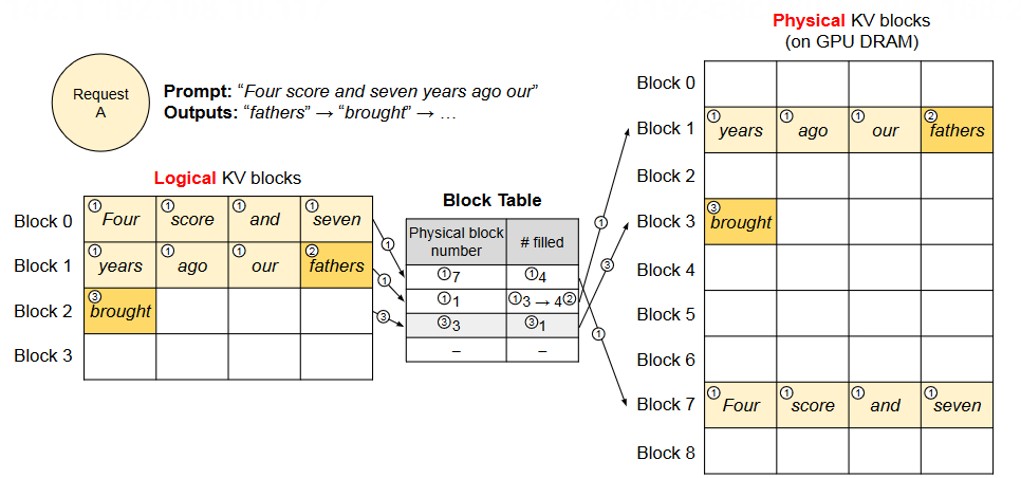
Prefill 阶段(对应图中步骤 1)#
逻辑块划分。按预设块大小(如 16 个 Token),将输入 prompt 拆分为连续的逻辑块(示例中 prompt 对应逻辑块 0 和逻辑块 1)。
物理块分配与映射。内存管理器从空闲物理块池中分配两个物理块,通过块表记录“逻辑块 0 → 物理块 1”“逻辑块 1 → 物理块 7”的映射关系。块表同时记录每个物理块的填充状态(
# filled字段表示已存储的 Token 数量)。
Decode 阶段(对应图中步骤 2/3)#
Attention 计算与 Token 生成。基于当前 KV Cache 计算注意力分数,生成第一个新 Token“fathers”。
块状态更新。新 Token 的 KV 向量需写入逻辑块 1,此时检查块表发现逻辑块 1 对应的物理块 7 仍有空闲槽位,直接写入并更新
# filled字段。新块分配。当逻辑块 1 的槽位被填满后,生成下一个 Token 时需开辟新逻辑块 2,内存管理器分配新物理块 8,更新块表映射关系。
2.4 多请求处理流程#
多请求并发处理时,PagedAttention 保持块表独立管理,核心逻辑如下:
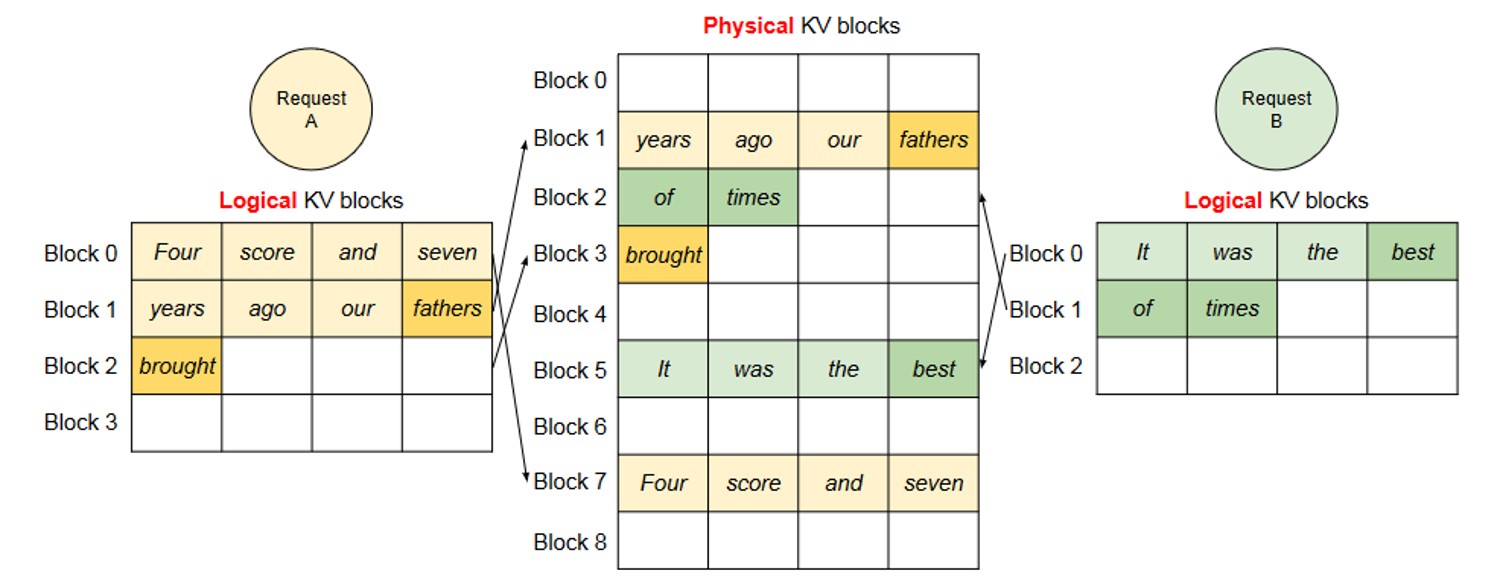
每个请求的逻辑块独立映射至物理块,不同请求的物理块可交叉分布在显存中,无需连续。
当某个请求完成推理(生成结束符或达到最大长度),其占用的所有物理块会被立即释放,归还至空闲物理块池,供新请求复用。
内存管理器统一维护物理块的分配状态,确保空闲块被高效利用,避免浪费。
3. 主流解码策略适配#
PagedAttention 的块表设计与物理块共享机制,天然适配大模型推理的各类复杂解码策略,以下为三大核心场景的适配方案:
3.1 Parallel Sampling#
Parallel Sampling 是指模型对单个输入 prompt 生成多个独立采样输出(如生成 3 个不同风格的回答),用户可选择最优结果。
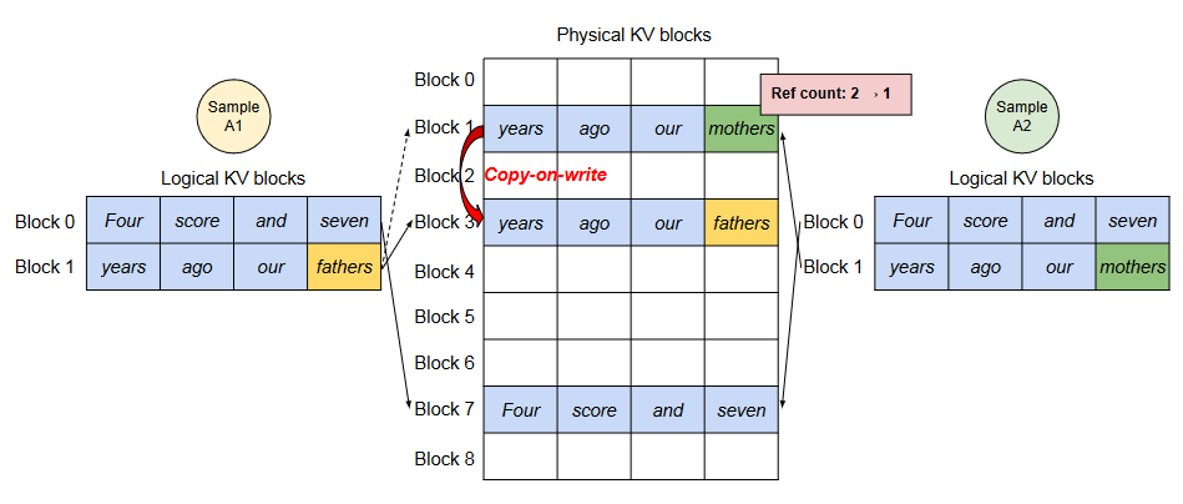
这类场景的核心优化点是 共享输入 prompt 的 KV Cache——多个输出序列的 prompt 部分完全一致,无需重复存储。PagedAttention 通过 写时复制(CoW)机制 实现这一优化,具体流程分为两阶段:
最大化共享(Prompt 处理阶段)。处理共同 prompt 时,所有输出序列的块表均指向同一组物理块(示例中物理块 1 和物理块 7)。系统为每个物理块维护 引用计数(reference count),记录当前被多少个序列共享(示例中物理块 1 的引用计数为 2)。
按需复制(Token 生成阶段)。新生成 Token 因采样差异各不相同,需单独存储 KV 向量:
当序列 A1 需向共享物理块 1 写入新 Token 时,系统检测到该块引用计数 > 1,触发写时复制:分配新物理块 3,复制原物理块 1 的全部内容,更新 A1 的块表(逻辑块 1 → 物理块 3),并将原物理块 1 的引用计数减 1。
序列 A2 写入物理块 1 时,其引用计数已降至 1,无需复制,直接写入新 Token 的 KV 向量。
通过这一机制,仅在实际写入不同内容时才产生复制开销,大幅降低长 prompt 场景的显存占用。
4.2 Beam Search#
Beam Search 是指每个解码步骤保留概率最高的 k 个 Token(k 为束宽),下一步骤基于这 k 个序列继续扩展,最终从 k 个完整序列中选择最优结果。该策略可提升输出质量,但会产生大量中间序列。
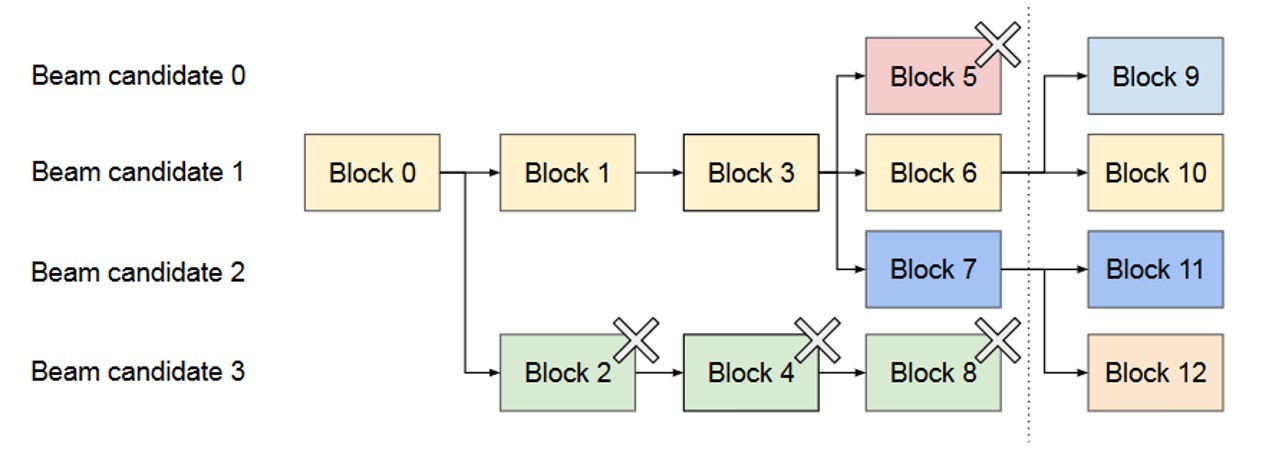
图中为 k=4 的束搜索示例,PagedAttention 对其的优化核心是 动态共享中间序列的 KV Cache:
不仅初始 prompt 对应的物理块可被所有束共享,解码过程中分支产生的相同前缀序列,其对应的物理块也可跨束共享。
随着解码推进,当不同束的 Token 选择出现分歧时,通过写时复制机制拆分共享物理块,确保各束的 KV Cache 独立更新。
共享模式随解码动态变化,始终保持最小化的显存占用,解决了传统束搜索因中间序列过多导致的显存爆炸问题。
3.3 Shared prefix#
Shared prefix 常见于翻译、问答等场景:用户输入由“任务描述前缀 + 实际任务内容”组成(如“将以下英文译为中文:Hello World”),多个用户的任务描述前缀完全相同。
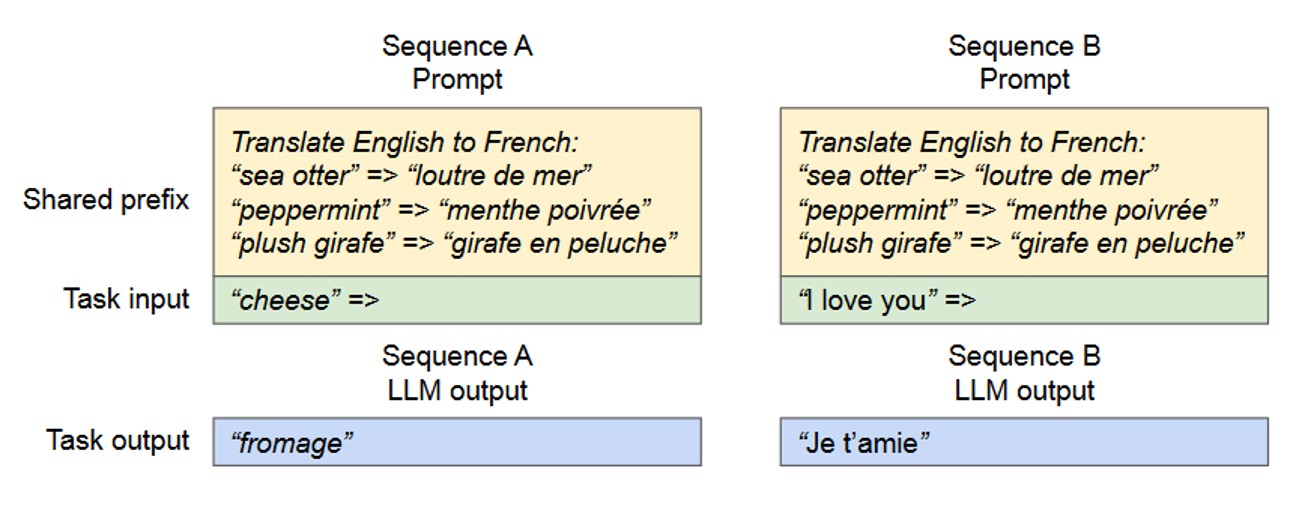
PagedAttention 针对该场景的优化的是 前缀 KV Cache 预存储与共享:
提前将公共前缀(如翻译任务描述、示例)的 KV Cache 计算并存储在显存中,类比操作系统的“跨进程共享库”,所有用户请求可直接复用该部分物理块,无需重复计算和存储。
仅需为每个用户的“实际任务内容”分配独立物理块,实时计算并存储其 KV Cache,大幅降低多用户并发时的显存开销与计算延迟。
4. 调度与抢占机制#
PagedAttention 解决了 KV Cache 的分配效率问题,而 vLLM 作为完整推理系统,还需通过合理的 请求调度与抢占机制 应对显存动态不足的场景。
4.1 核心调度策略#
vLLM 采用 “FCFS + 后到先抢占” 的混合调度策略,平衡公平性与吞吐量:
先到先服务(FCFS)。优先处理早到达的请求,保证公平性并防止请求饥饿(长期未被处理)。
后到先抢占(Latecomer Preemption)。当显存不足时,优先暂停后到达的请求,释放其 KV Cache 物理块,为早到达的请求腾出空间,确保核心请求能快速完成。
这一策略的合理性在于:大模型推理请求的 prompt 长度、输出预期长度差异极大,若采用纯 FCFS 可能导致长请求阻塞大量短请求,通过抢占可动态调整资源分配。
4.2 抢占触发与执行#
动态内存分配模式下,若所有已分配物理块均被占用(显存打满),且所有请求均未完成推理,vLLM 会触发抢占机制:
执行策略:采用 all-or-nothing 抢占——即一次性释放被抢占请求的所有物理块,而非部分释放,避免残留物理块导致的外部碎片。
触发优先级:优先抢占后到达的请求,且优先选择输出长度较短、剩余推理步骤少的请求(降低恢复成本)。
4.3 被抢占任务恢复策略#
被抢占的请求需在显存充足时恢复,vLLM 提供两种恢复机制,核心差异在于 KV Cache 的保留方式:
Swapping(交换恢复)#
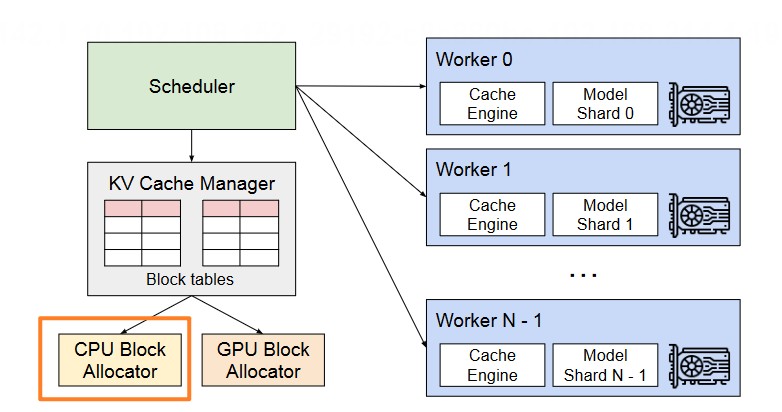
原理:借鉴虚拟内存的交换机制,将被抢占请求的 KV Cache 物理块数据拷贝至 CPU 内存(而非磁盘,避免 IO 延迟),并记录块表映射关系。
架构:vLLM 同时维护 GPU 块分配器与 CPU 块分配器,CPU 块分配器专门管理交换过来的物理块数据。
恢复流程:当显存充足时,将 CPU 内存中的物理块数据重新加载至 GPU 显存,恢复块表映射,请求继续推理。
Recomputation(重计算恢复)#
原理:抢占时直接释放被抢占请求的 GPU 物理块,不保留 KV Cache 数据;恢复时无需加载数据,而是重新输入 prompt,从头计算并重建 KV Cache。
优势:无需占用 CPU 内存,也无数据拷贝开销,实现简单。
4.4 恢复策略选择依据#
两种恢复机制的选择核心取决于 物理块大小,本质是权衡数据拷贝开销与重计算开销:
对比维度 |
Swapping(交换) |
Recomputation(重计算) |
|---|---|---|
开销与块大小关系 |
强相关——块越小,拷贝次数越多,PCIe 带宽利用率越低,开销越高 |
弱相关——与块大小无关,开销稳定(仅取决于序列长度) |
内存占用 |
占用 CPU 内存存储 KV Cache |
不占用额外内存 |
恢复延迟 |
取决于数据量(块大小 × 块数) |
取决于序列长度(需重新计算 Attention) |
基于以上特性,vLLM 的自适应选择策略为:
块较小时(如 16 Token/块):重计算效率更高,避免频繁 CPU-GPU 小数据拷贝。
块较大时(如 64 Token/块):交换机制更优,单次拷贝数据量充足,能充分利用 PCIe 带宽,开销低于重计算长序列的成本。
5. 分布式场景适配#
随着模型规模增长(如 100B+ 参数),单张 GPU 已无法容纳整个 LLM 的参数,需采用 模型并行(Model Parallelism) 技术,将模型层、注意力头拆分至多张 GPU 协同工作。PagedAttention 针对分布式场景设计了“中心化管理 + 分布式执行”的内存管理方案。
5.1 核心设计思想#
vLLM 分布式内存管理的核心是 “中心化 KV Cache 管理,分布式计算执行”,架构如下:
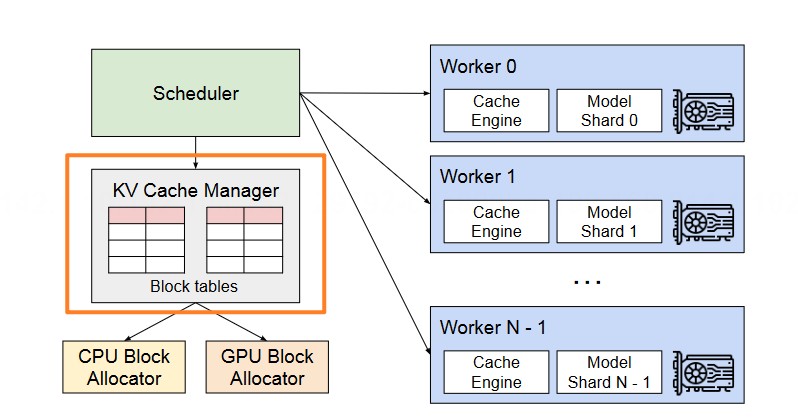
中心化管理:设置一个 中央 KV Cache 管理器(部署在主 GPU 或 CPU),负责全局逻辑块到物理块的映射计算、物理块分配调度、跨 GPU 块表同步。
分布式执行:所有 GPU Worker 共享统一的块表映射关系——中央管理器将分配好的块表广播给所有 GPU,每张 GPU 仅负责管理本地显存中的 KV 物理块,执行本地对应的 Attention 计算。
5.2 关键技术细节#
块表广播机制:中央管理器实时更新块表,通过高速互联(如 NVLink)将更新同步至所有 GPU Worker,确保各 GPU 对 KV Cache 位置的认知一致。
跨 GPU 数据访问:当某 GPU Worker 需要访问存储在其他 GPU 的 KV 物理块时,通过分布式通信接口(如 NCCL)直接读取,避免数据冗余拷贝。
负载均衡:中央管理器根据各 GPU 的显存使用率、计算负载,动态分配物理块,避免单 GPU 显存过载或计算瓶颈。
6. Attention 算子适配优化#
PagedAttention 的分页机制解决了内存管理问题,但也引入新挑战:逻辑上连续的 KV Cache 物理上分散存储,而传统 Attention 算子是为 连续内存块 设计的,直接使用会导致大量随机内存访问,GPU 并行计算能力无法发挥,性能严重下降。
为此,vLLM 重新设计了 PagedAttention 定制化算子,使其原生适配非连续内存布局,核心是让 Attention Kernel 支持“按块读取-计算-累加”的迭代模式。
6.1 Kernel 核心逻辑#
Attention 计算的本质是矩阵运算:\(output = softmax(Q @ K^T) @ V\)(其中 Q 为查询向量,K/V 为 KV Cache 向量)。在 PagedAttention 中,K 和 V 被拆分为多个非连续物理块,因此该矩阵运算被拆解为 小数据块的迭代计算过程,核心步骤如下:
对于批次中的每个查询向量 \(q_i\)(对应单个 Token 的查询):
块表查找。根据 \(q_i\) 所属序列,从块表中获取该序列所有 K/V 物理块的索引。
迭代块计算。遍历每个物理块,加载对应的 K 块(\(K_{block}\))和 V 块(\(V_{block}\)),计算 \(q_i\) 与 \(K_{block}\) 的注意力分数 \(S_{ij} = q_i @ K_{block}^T\)。
在线 Softmax 与加权累加。为避免存储完整注意力分数矩阵(显存开销大),采用 在线 Softmax 算法:
实时更新 Softmax 统计量(当前最大注意力分数 \(m_i\)、指数和 \(l_i\))。
根据当前块的注意力概率 \(P_{ij} = exp(S_{ij} - m_{new})\)(\(m_{new}\) 为累计最大分数),对 \(V_{block}\) 加权求和,累加到中间输出向量 \(o_i\)。
最终归一化。所有块遍历完成后,通过 \(o_i / l_i\) 得到最终输出向量。
6.2 核心伪代码解析#
以下伪代码精准描述 PagedAttention Kernel 的迭代计算与在线 Softmax 逻辑:
# PagedAttention Kernel 伪代码描述
# 输入:
# Q: [num_queries, head_dim],查询向量(num_queries 为批次中查询总数)
# KV_Cache: 存储所有 K, V 块的物理内存(按块索引访问)
# Block_Tables: [num_queries, max_blocks_per_seq],每个序列的物理块索引表
# 输出:
# Output: [num_queries, head_dim],最终注意力输出向量
function PagedAttention(Q, KV_Cache, Block_Tables):
# 初始化输出张量(与查询向量维度一致)
Output = zeros_like(Q)
# 对每个查询向量并行计算(GPU 多线程并行)
for each query q_i in Q:
# 获取当前查询所属序列的物理块索引表
block_table_for_q_i = Block_Tables[i]
# 初始化在线 Softmax 核心统计量
m_i = -infinity # 累计最大注意力分数(避免指数溢出)
l_i = 0.0 # 累计指数和(Softmax 分母)
o_i = zeros(head_dim) # 累计输出向量
# 迭代遍历当前序列的所有 K/V 物理块
for each block_idx in block_table_for_q_i:
# 从物理内存加载当前块的 K 和 V 向量(非连续访问)
K_block = KV_Cache.get_K(block_idx) # 形状:[block_size, head_dim]
V_block = KV_Cache.get_V(block_idx) # 形状:[block_size, head_dim]
# 计算当前块的注意力分数(单个查询 vs 块内所有 Key)
S_ij = q_i @ K_block.T # 形状:[block_size]
# 在线更新 Softmax 统计量(核心优化:避免存储完整 S 矩阵)
m_ij = max(S_ij) # 当前块的最大注意力分数
m_new = max(m_i, m_ij) # 累计最大注意力分数(更新)
# 按新最大分数重缩放历史统计量(防止指数溢出)
P_ij = exp(S_ij - m_new) # 当前块注意力概率(归一化)
l_i = l_i * exp(m_i - m_new) # 重缩放历史指数和
o_i = o_i * exp(m_i - m_new) # 重缩放历史输出向量
# 累加当前块的统计量
l_new = l_i + sum(P_ij) # 累计指数和更新
o_i = o_i + P_ij @ V_block # 输出向量累加(注意力加权)
# 更新统计量,进入下一块迭代
m_i = m_new
l_i = l_new
# 最终归一化:得到单个查询的注意力输出
Output[i] = o_i / l_i
return Output
6.3 配套优化措施#
为进一步降低算子开销,vLLM 还实现了两项关键融合优化:
融合 KV Cache 写入。每个 Token 生成后,新 K/V 向量需执行“重塑 → 切分 → 写入物理块”三步操作。vLLM 将这三步融合为 单个 GPU Kernel,避免多次 Kernel 启动开销(GPU Kernel 启动延迟约 1-10us,累计影响显著)。
批处理写时复制(CoW)。在 Beam Search 等场景中,需同时拷贝多个分散的物理块。vLLM 实现 批处理拷贝 Kernel,将多个独立拷贝请求打包为一次 GPU 任务,充分利用 GPU 并行拷贝能力,提升拷贝效率。
7. 核心价值与总结#
大模型推理服务的核心瓶颈是 GPU 显存利用率——常规静态预分配方式因内部/外部碎片、无法共享内存等问题,导致显存浪费严重,直接限制系统吞吐量。
vLLM 提出的 PagedAttention 算法,通过借鉴操作系统虚拟内存的分页思想,将 KV Cache 拆分为固定大小的物理块,用块表管理逻辑与物理映射,从根本上解决了传统内存管理的痛点。
基于 PagedAttention 及配套优化(调度抢占、算子融合),vLLM 实现了显存利用率与吞吐量的大幅提升,成为大模型推理领域的标杆框架,其设计思想也为其他资源管理场景提供了重要参考。
引用与参考#
[1] 字节跳动技术团队. vLLM 核心技术:PagedAttention 详解 (EB/OL). (2023-08-15) (2025-11-03). https://zhuanlan.zhihu.com/p/691038809.
[2] Zhang J, Li M, Xiao C, et al. Efficient Memory Management for Large Language Model Serving with PagedAttention(Preprint/OL). (2023-09-25) (2025-11-03). https://arxiv.org/pdf/2309.06180.
[3] AI 前线。深入理解 vLLM:高性能 LLM 推理框架的核心技术 (EB/OL). (2023-07-20) (2025-11-03). https://zhuanlan.zhihu.com/p/673284781.